An analysis of 44,684 web pages reveals a median content length of 3,201 tokens and an average of 10,403 tokens, highlighting implications for AI systems.
How big is the average web page? A recent analysis of nearly forty-five thousand web pages reveals a surprising gap between what we expect and what is actually out there.
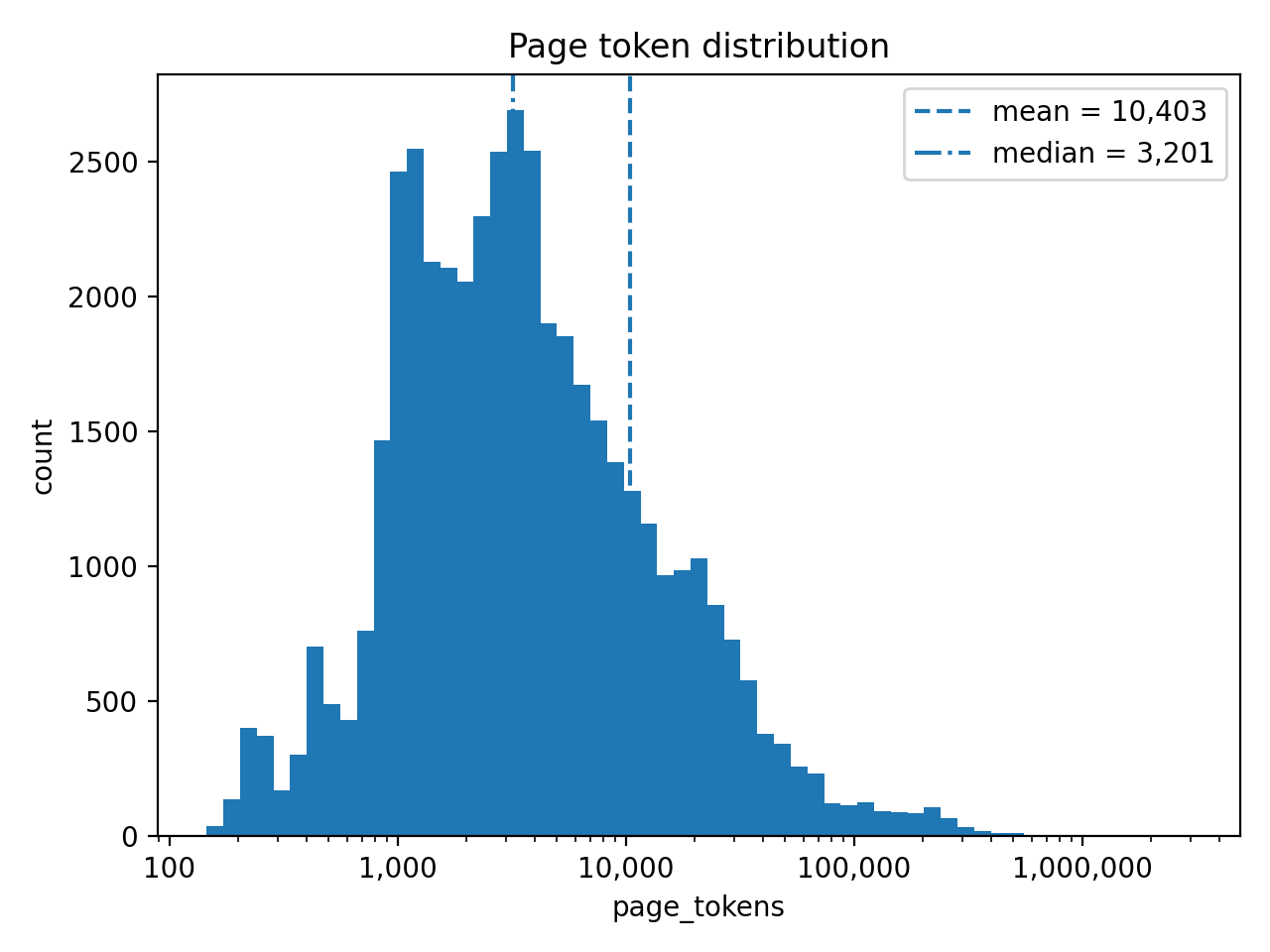
The median web page contains about thirty-two hundred tokens, which is roughly twenty-four hundred words. But the average is much higher, coming in at over ten thousand tokens. This is because the web has a very long tail of massive documents. While half of all pages sit between one thousand and five thousand tokens, the top one percent exceed one hundred and forty thousand tokens.
This distribution has major implications for artificial intelligence. If you are building Retrieval-Augmented Generation systems, ninety-five percent of web pages will fit comfortably within a standard context window. But because of those massive outliers, average processing costs can be three times higher than the median.
Most people underestimate how much content is on a typical page. To build efficient systems, you need to design for the typical three-thousand-token article, while making sure your system can handle the occasional giant document.

We recently analyzed 44,684 web pages and measured their content length using Gemini’s token counter. The results reveal fascinating insights about the true scale of web content—and why it matters for AI applications.
| Metric | Value |
|---|---|
| Total Pages Analyzed | 44,684 |
| Page Content Tokens | 464,854,727 |
| Total Tokens (all) | 541,062,817 |
The median web page contains roughly 3,200 tokens—equivalent to about 2,400 words or approximately 5 pages of text. However, the average is significantly higher at 10,400 tokens, indicating a strong right-skew from lengthy documents.
| Metric | Tokens |
|---|---|
| Median | 3,201 |
| Average | 10,403 |
| 25th percentile | 1,396 |
| 75th percentile | 8,207 |
Half of all web pages fall between 1,000 and 5,000 tokens. This represents the “typical” article, blog post, or informational page.
| Token Range | Pages | Percentage |
|---|---|---|
| 0 – 1,000 | 6,229 | 13.9% |
| 1,000 – 5,000 | 22,299 | 49.9% |
| 5,000 – 10,000 | 6,629 | 14.8% |
| 10,000 – 50,000 | 8,048 | 18.0% |
| 50,000 – 100,000 | 806 | 1.8% |
| 100,000 – 500,000 | 657 | 1.5% |
| 500,000+ | 16 | 0.04% |
Nearly 1 in 5 pages (18%) contain between 10,000 and 50,000 tokens—these are longer articles, comprehensive guides, or pages with significant supplementary content.
Percentile analysis reveals the extreme outliers:
| Percentile | Tokens |
|---|---|
| 90th | 21,839 |
| 95th | 35,852 |
| 99th | 141,410 |
| Maximum | 3,004,502 |
The top 1% of pages exceed 140,000 tokens—roughly 100+ pages of text. These are typically:
The largest page in our dataset contained over 3 million tokens—equivalent to approximately 4-5 full-length novels.
With major LLMs offering context windows from 32K to 2M tokens, our findings suggest:
For Retrieval-Augmented Generation systems:
url_context toolWhile the typical page sits around 3,000 tokens, the distribution has a remarkably long tail. AI systems consuming web content need to account for this variance—both for context management and cost optimization.
For practical applications:
Before publishing this analysis, I ran a poll on LinkedIn asking people to predict the average page size in tokens:
| Guess | Votes | Percentage |
|---|---|---|
| 100 | 27 | 21% |
| 1,000 | 50 | 38% |
| 10,000 | 45 | 34% |
| 100,000 | 9 | 7% |
131 people voted. The most popular answer was 1,000 tokens (38%), followed closely by 10,000 tokens (34%). The actual answer? 10,403 tokens on average.
Only a third of respondents got it right. The majority underestimated—perhaps expecting a page of text to be shorter than it actually is when tokenized. What’s interesting is that the median (3,201 tokens) would have made “1,000” a more defensible answer, but averages get skewed heavily by those outlier documents.
The 7% who guessed 100,000 weren’t entirely wrong either—they just described the 99th percentile rather than the average.
 Dan Petrovic ·
Dec 14, 14:11
Dan Petrovic ·
Dec 14, 14:11
Yeah those million token URLs really broke my pipeline and I was wondering if there was bug in my code, spent days trying to figure it out and then I LOOKED AT THE DATA and was like… oh…..
Dan Petrovic ·
Supports · ·
Dec 25, 05:10
I wonder if cost is the same always or maybe the initial chunking cost more but – as long as they don’t want to rerank the answer – it doesn’t cost at all.
I’d say their chunking pipeline is the most efficient one on the planet and would love to get my hands on it 🙂
Dan Petrovic ·
Supports · ·
Dec 25, 05:11
The more I learn from your research studies, the less I think OpenAI can win (I’m saying this with $ on the table)
Thank you for doing both median, mode, and explaining those edge cases.
It’s funny how the outlier data you see in school – the ones you’d throw out – are in practice the hard problems that tell you what organizations are shooting to be that 99th percentile…
Because when you operate in the trillions, your errors are in the millions.
Scale always messes with my mind.
It’ll be very interesting to see what comes next on the web now that machine translations become more acceptable. Will we see model collapse or will there finally be better multilingual results and answers?
Thank you for sharing the kind of 99th percentile work as well.
*No AI was used and I should get back to sleep.