Machine learning models
Each model we train does one thing only, and does it really well. Interested in hearing how we can transform your SEO using machine learning techniques?
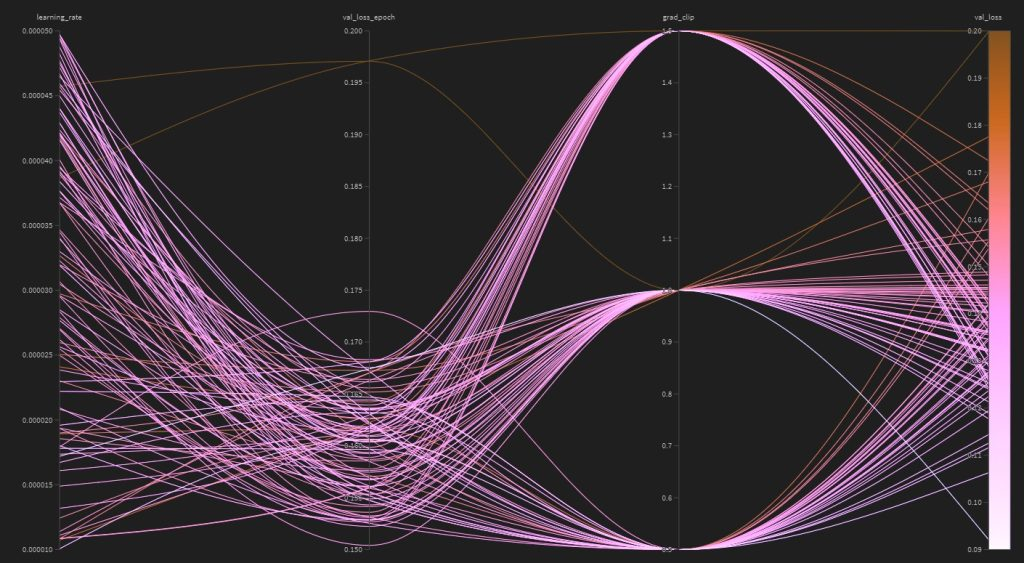
DeBERTa-v3 · Binary classifier
Binary classification model for detecting AI-generated vs human-written text. A fine-tuned DeBERTa-v3 model trained to distinguish between organic (human-written) and AI-generated content. Uses class-weighted training to handle imbalanced datasets and is optimized for high precision in content authenticity detection.
Key features
Use cases
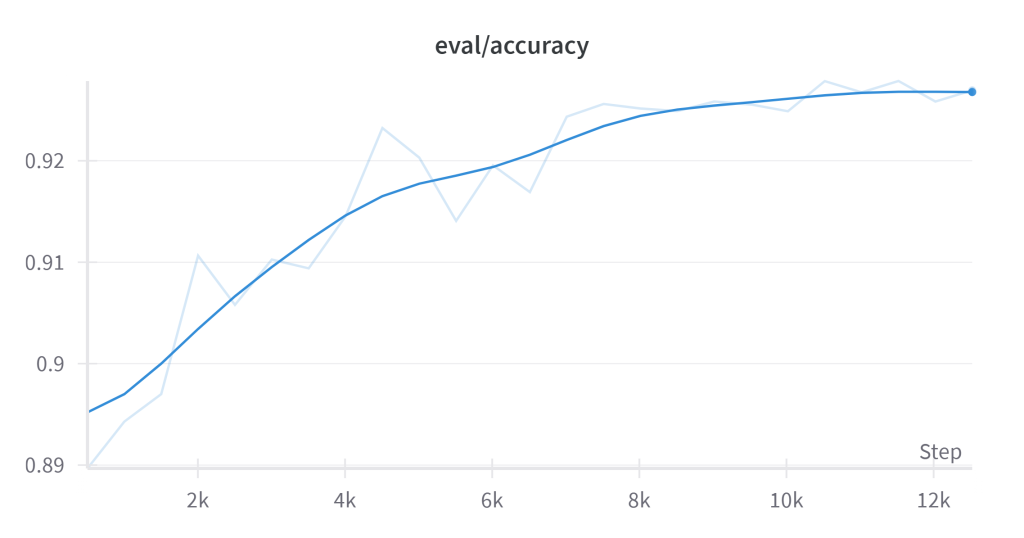
Money-link detection
Link spam algorithm which can identify money links on any page. If our algorithm can spot your link, so can Google’s, and that means that your links are either being devalued or pose a risk of penalty.
Batch processing
Multilingual T5 · Query expansion
The model generates diverse, contextually relevant search query variations for a given URL and seed query. By reformulating queries, it helps capture a broader range of search intents, improving organic search visibility and click-through rates.
This is especially valuable for SEO, content optimization, and keyword targeting, enabling discovery of traffic-driving variations that may not surface through manual keyword research.
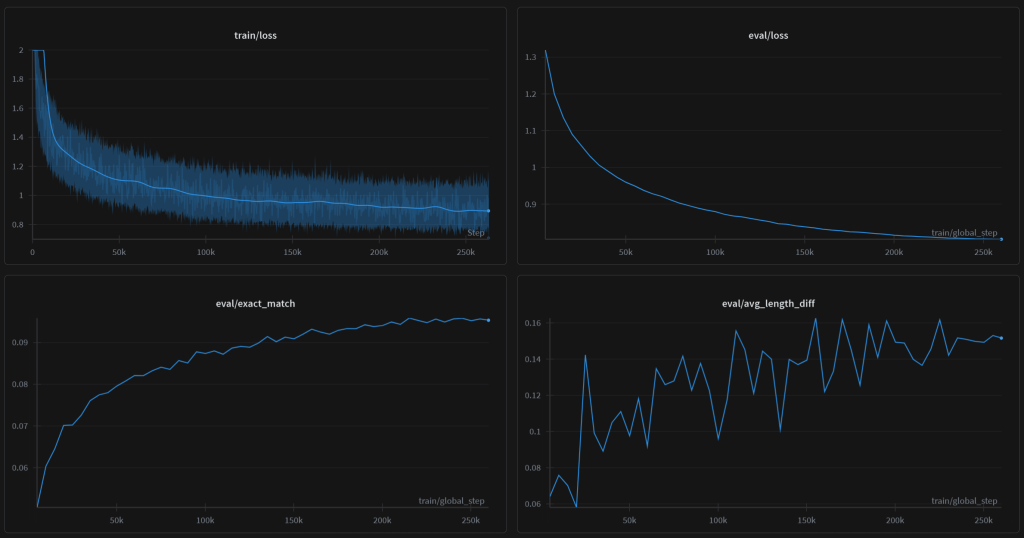
Inference: High Effort (Deep Analysis)
Inference: Quick Fan-Out
Training ran for 70 hours, 5 times over 15 million training samples.
Rigorously following all available steps in Google’s query fan-out process we train a search query reformulation model with optimization and improvements geared towards SEO use. In the two-step process we first create a custom architecture Gemma 3 1B for feature extraction and use it to augment our training data via interpolation between the query and the target documents using vector embedding space traversal. Combining Google Search Console data (query and URL pairs) augmented with synthetic data we then fine-tune a large multilingual T5 model for query expansion.
Open-set · Multi-label
Generalist, open-set classification for any label taxonomy.
Multi-label text classification for search queries with arbitrary label support. The Universal Query Classifier is a specialized model for classifying search queries into multiple intent categories simultaneously. Unlike traditional single-label classifiers, this model supports threshold-based multi-label assignment and works with any custom label set.
Key features
Use cases
Model variants
ALBERT · Multi-label intent
Multi-label search query classification model developed by Dejan AI. The model is designed to be deployed in an automated pipeline capable of classifying search query intent for large volumes of search queries from common data sources such as ad campaigns and organic search tools and platforms.
Classification labels
Models: dejanseo/Intent-XS · dejanseo/Intent-XL
BERT · Anchor-text prediction
LinkBERT is a fine-tuned version of Google’s BERT model, designed to predict natural link placement within web content. This binary classification model excels in identifying distinct token ranges that web authors are likely to choose as anchor text for links. By analysing never-before-seen texts, LinkBERT can predict areas within the content where links might naturally occur, effectively simulating web author behaviour in link creation.
LinkBERT is positioned as a powerful tool for content creators, SEO specialists, and webmasters, offering unparalleled support in optimizing web content for both user engagement and search engine recognition.
Use cases
Models: dejanseo/LinkBERT · LinkBERT-mini · LinkBERT-XL
7-point · Multi-label sentiment
Multi-label sentiment classification model developed by Dejan Marketing. The model is designed to be deployed in an automated pipeline capable of classifying text sentiment for thousands (or even millions) of text chunks or as a part of a scraping pipeline.
Classification labels
Sources of training data
Models: dejanseo/sentiment · dejanseo/good-vibes
ALBERT · Well-formedness
We build on the work by Manaal Faruqui and Dipanjan Das from Google AI Language team to train a search query classifier of well-formed search queries. Our model offers a 10% improvement over Google’s classifier by utilising ALBERT architecture instead of LSTM.
Practical application
Our robust model validation process ensures model quality for most common classification and natural language processing tasks.
Recall
Precision
Accuracy
F1
Bespoke
Our team can work with you to design and train your very own industry-, language- or task-specific model.
Example: Bulgarian Search Query Intent
Book a conference call with our team to discuss a custom model for your industry, language or task.