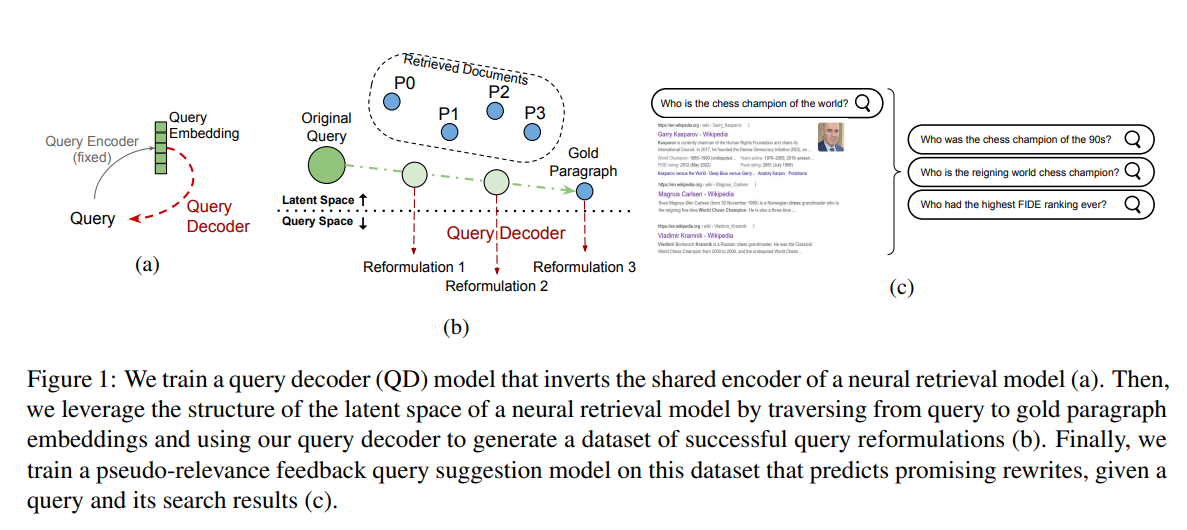
Google generates high-quality query reformulations by traversing the mathematical latent space between queries and documents to train the qsT5 model.
Google has discovered a way to generate millions of high-quality search suggestions without any human input. They did it by teaching artificial intelligence to navigate the mathematical space between what a user types and the documents they are trying to find.
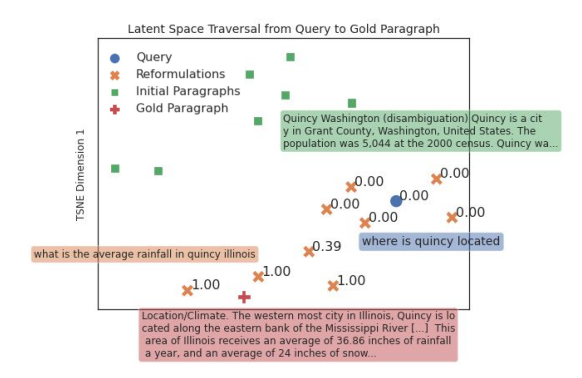
In modern search engines, queries and documents are translated into lists of numbers called vector embeddings. Words with similar meanings cluster together in this mathematical neighborhood. Google's breakthrough was realizing they could start at a user's query, draw a straight line directly to the target document, and take step-by-step strides along that path.
To make sense of these steps, they built a query decoder. This tool translates the mathematical points along the path back into readable text. For example, a search for "average yearly return on stock market" slowly and logically morphs into "average annual return of the S and P stock exchange."
Using nearly a million of these generated pathways, they trained a model called Query Suggestion T5. In action, the model doesn't need to perform complex vector math. It has internalized how to navigate this space. By looking at a user’s initial search and the first few results, it instantly figures out the underlying intent and generates multiple, highly accurate variations.
This approach significantly improves search accuracy. More importantly, it shifts how we think about search. Instead of treating queries as rigid, fixed strings of text, we can now view them as starting points for a journey through meaning.

qκ = q + κ/k(d − q)This generated 863,307 training examples for a query suggestion model (qsT5) that outperforms all existing baselines.
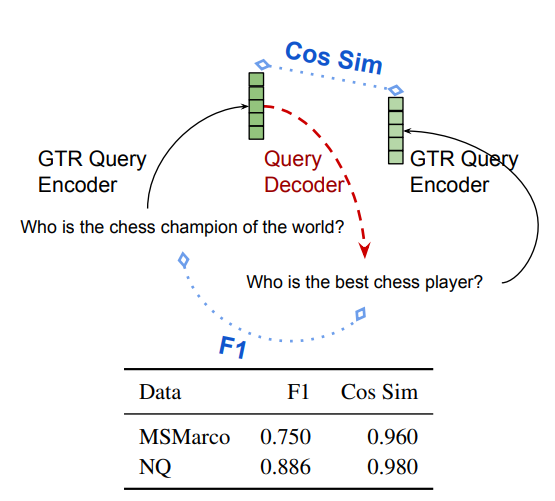
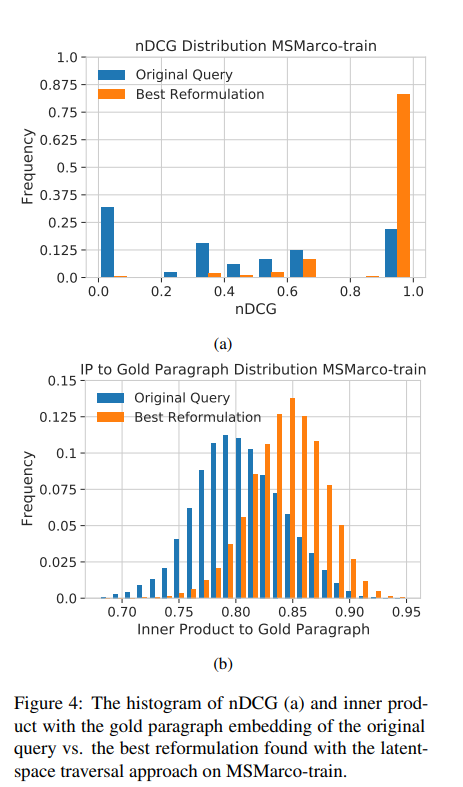
First, they trained a T5 model to invert Google’s GTR search encoder. Feed it any embedding vector, and it generates the query that would produce that embedding. This achieved 96% cosine similarity on reconstruction, nearly perfect fidelity.

Starting with MSMarco query-document pairs:
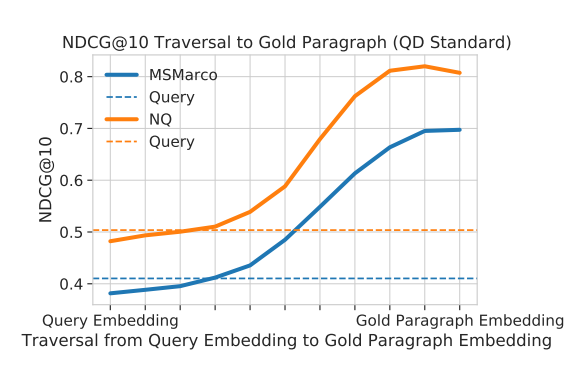
Example traversal from “average yearly return on stock market”:
Step 0: “average yearly return on stock market” [nDCG: 0.0] Step 5: “what is the average return in a stock market” [nDCG: 0.0] Step 12: “what is the average return on the s&p stock exchange” [nDCG: 0.36] Step 20: “what is the average annual return of the s&p stock exchange” [nDCG: 1.0]
Using this synthetic dataset, they fine-tuned T5-large with two variants:
Modern neural retrievers like GTR embed queries and documents in the same vector space where semantic similarity equals geometric proximity. The researchers’ insight: if relevant documents cluster in certain regions, then moving toward those regions should produce better queries.
The elegance lies in three key observations:
Here’s the fascinating part: while training data comes from explicit geometric traversal, the final qsT5 model operates without any vector arithmetic. It has internalized the traversal patterns.
When qsT5 sees “python loops” + search results about programming:
q + α(d − q)The model essentially compresses thousands of traversal examples into an implicit understanding of how to navigate query space.
In deployment, the system works like this:
Performance gains:
Original Query
who created spiritual gangster
MQR
Who created the Spiritual Gangster?
Who created the “spiritual gangster” storyline?
Who created the “spiritual gangster”?
RM3
who created spiritual gangster spiritual
who created spiritual gangster modern
who created spiritual gangster inspired
Sampling+QD
who created gangster a spiritual & egantious
who created spiritual gangster -gangster
who created spiritual gangster
qsT5
who is the founder of spiritual gangsters
who created the spiritual gangster ( spiritual yogi )
what is the spiritual gangster movement
qsT5-plain
who are the founders of the gangster spirit band
how many gangsters were formed in white supreme
who was the members of the gangster supremes
The qsT5 model with PRF significantly outperforms the query-only version because:
The model learns to extract signals from initial results and incorporate them into reformulations, mimicking how human searchers refine queries after seeing preliminary results.
This approach enables:
By framing query reformulation as navigation in latent space, this work opens new possibilities:
The key insight: instead of treating queries as fixed strings, we can view them as starting points for journeys through meaning space. The AI has learned to be an expert guide for these journeys.
https://arxiv.org/pdf/2210.12084
https://patents.google.com/patent/US20230281193A1/en
 Dan Petrovic ·
Jun 24, 01:18
Dan Petrovic ·
Jun 24, 01:18
Thank you Brian! Love to see that the research clicks with people, it’s very exciting stuff.
Dan Petrovic ·
Supports · ·
Jul 10, 01:00
Hi Dan, I couldn’t ask for a better way to spend my Easter Monday than reading your posts. You’re the Einstein of our industry, and I’m a huge fan. Plus, you’re helping me solve a critical problem for one of my very important clients. Best regards from Berlin
Much love from Brisbane, Australia! 🙂
Keep me posted with your work.
Dan Petrovic ·
Supports · ·
Apr 07, 03:35
Please correct me if I’m misunderstanding you: Based on my understanding of “pseudo-relevance,” I’d like an example involving providers in the broader healthcare sector. Google clearly responds positively when psychotherapists not only present their services but, more importantly, describe the flow of a session—ideally on their homepage. This also aligns with feedback from my clients, who report that this question is asked very frequently by new potential patients. However, this also works for a dentist, where the “process” section might include something like: “You call, we schedule an appointment, then you come to the dental office for your appointment.” In my opinion, this is essentially fluff content, and the dentist also believes that this information is never actually requested in this form. Nevertheless, Google responds positively to such information, which I believe stems from a general trend among healthcare providers. I would really appreciate a quick response from you to confirm whether I’ve understood this correctly. Best regards from Berlin
Ah… I already have a tool that optimizes for model preference using a specially designed algorithm. Ping me on LinkedIn for details.
Dan Petrovic ·
Expands ·
Apr 15, 03:54
This is really great and insightful. I’m more concerned on practicality does this show relevance to performant keywords. And thanks for sharing.
The research you put out is simply phenomenal. Thank you for making this public…