RexBERT is a domain-specialized language model trained on e-commerce text to optimize product titles, descriptions, attribute extraction, and semantic search.
Imagine a language model built specifically for the quirks of online shopping. That is RexBERT. Unlike general-purpose AI, RexBERT is trained on massive amounts of e-commerce text, from product descriptions and customer reviews to frequently asked questions.
For search engine optimization, or SEO, this model is a game-changer. It helps bridge the gap between how search engines interpret product pages and how real people actually search.
You can use RexBERT to automatically spot missing product details, like a size that is mentioned in a description but left out of the main title. It is also highly effective at pulling structured attributes out of messy text to power website filters, and it easily connects synonyms like sneakers and trainers to improve internal site search. On top of that, it can detect duplicate content across giant catalogs and even simulate how your product titles will look on search engine results pages before you publish them.
In performance benchmarks, RexBERT consistently beats larger, generic models on retail tasks. Even better, it is available in lightweight versions that run quickly and affordably, making real-time automation highly practical.
Ultimately, RexBERT allows you to clean up your product catalogs, improve your search presence, and create a much smoother journey for your buyers.

RexBERT is a domain-specialized language model trained on massive volumes of e-commerce text (product titles, descriptions, attributes, reviews, FAQs). Unlike general-purpose transformers, it is optimized to understand the quirks of product data and the way consumers phrase queries. For a technical SEO professional, this means better alignment between how search engines interpret product content and how you can optimize it.
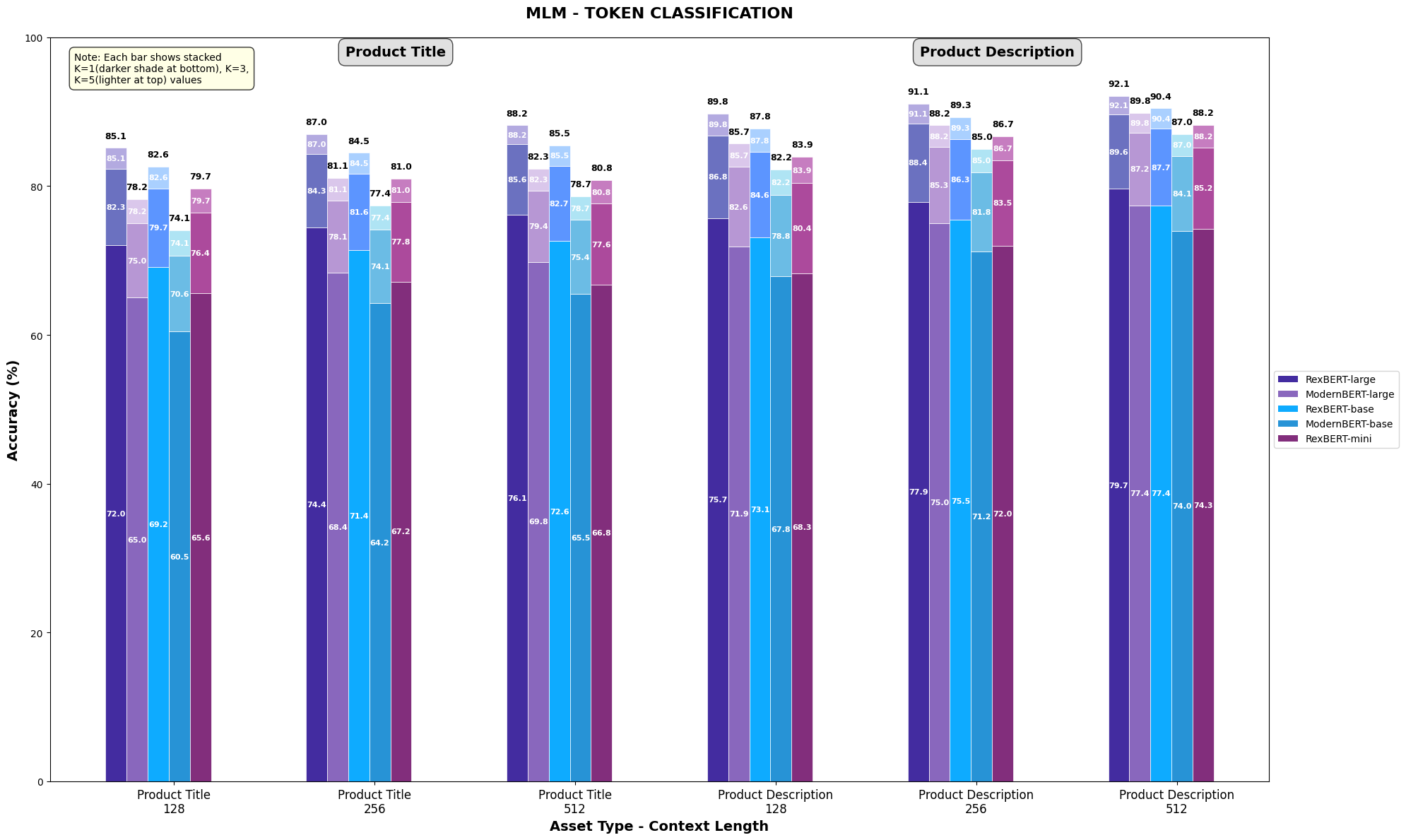 The study utilized textual data assets from the Amazon ESCI dataset to benchmark model performance. Evaluations were conducted using the ‘Product Title’ and ‘Product Description’ fields with three distinct context window sizes: 128, 256, and 512 tokens.
The study utilized textual data assets from the Amazon ESCI dataset to benchmark model performance. Evaluations were conducted using the ‘Product Title’ and ‘Product Description’ fields with three distinct context window sizes: 128, 256, and 512 tokens.
Across the English ESCI similarity task, the RexBERT series consistently outperforms other models within a similar parameter budget. Notably, RexBERT-large achieves the strongest performance, surpassing EmbeddingGemma-300M under identical training and evaluation conditions.
For a technical SEO in e-commerce, RexBERT isn’t just another NLP model – it’s a tool to operationalize SEO at scale, automating the detection of content gaps, improving site search, and ensuring structured data integrity. The payoff: cleaner catalogs, stronger SERP presence, and more frictionless buyer journeys.
Checkpoints:
 Dan Petrovic ·
Sep 23, 08:13
Dan Petrovic ·
Sep 23, 08:13
Sign in with Google to comment.