An analysis of reducing vector embedding storage through Matryoshka Representation Learning and binary embeddings to optimize SEO text feature extraction.
If you use vector embeddings for advanced SEO analysis, you know how quickly they can eat up terabytes of storage on large websites. But it turns out, we might be wasting a massive amount of time, money, and hard drive space.
By combining Matryoshka Representation Learning with binary embeddings, you can drastically reduce the size of your files with almost no loss in quality. Testing shows that after reducing your embeddings to two hundred and fifty-six dimensions, you hit true diminishing returns.
To put this in perspective, a modern binary embedding at just eight dimensions performs on par with the original, full-sized BERT model.
By embracing these lean, high-efficiency binary embeddings, you can build search engines and clustering tools that are incredibly fast, cheap, and powerful, without the heavy storage burden.
When conducting an advanced SEO analysis, I frequently utilise vector embeddings for text feature extraction, similarity searches, clustering, retrieval, ranking and so on. One of the main burdens on top of compute is storage space, as these files tends go into terabytes for very large websites. Today I did a deep analysis and realised I’ve been wasting time, money and hard drive space this whole time.
I started with a SOTA embedding model and tested the quality of vector embeddings after applying:
a. Matryoshka Representation Learning (MRL)
b. Binary Embeddings
c. Combined Both
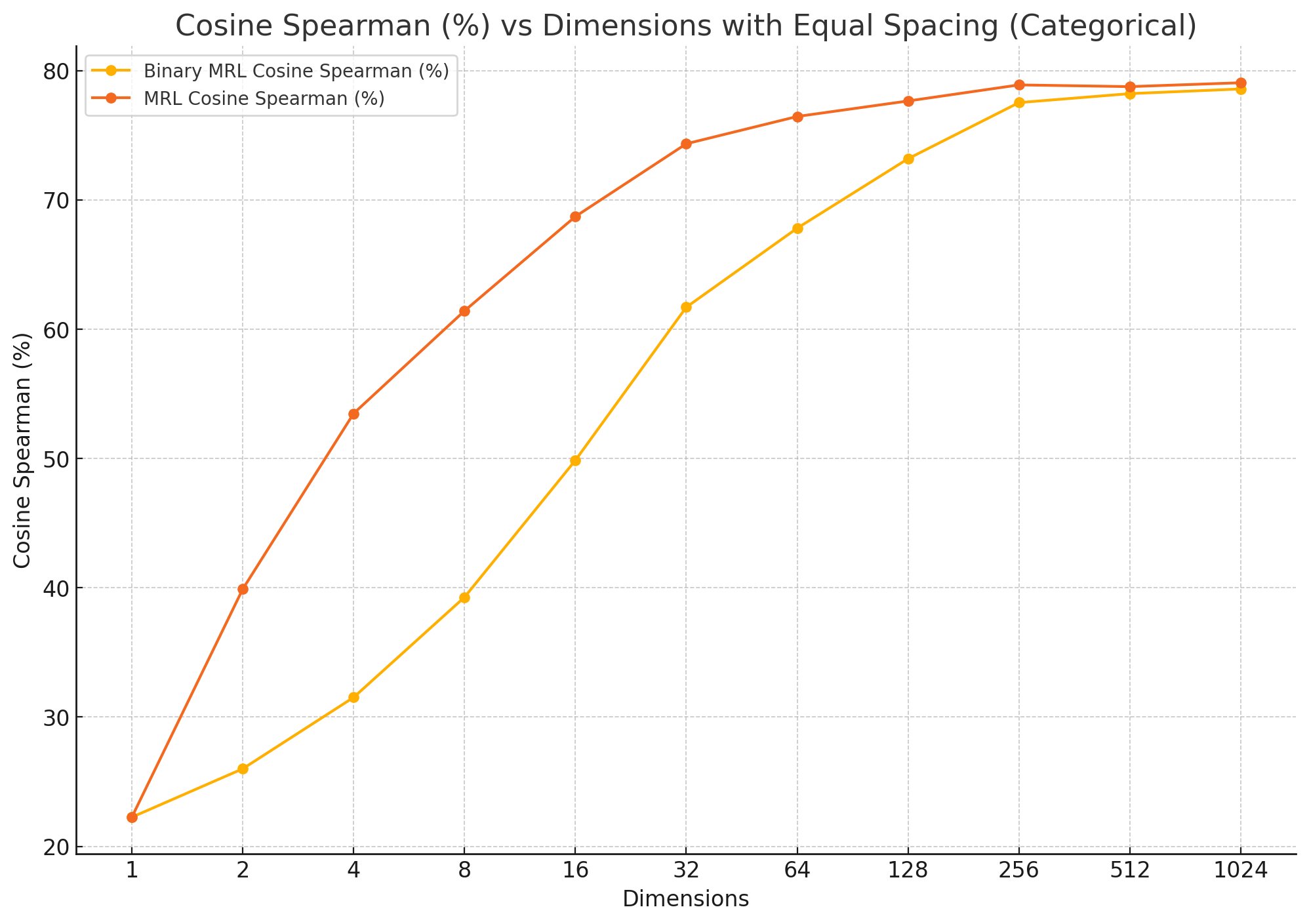
Y = cosine spearman on MTEB/STS12 dataset.
X = embedding dimensionality reduction via MRL.
Here’s how much hard drive space I need for each vector embedding, binary vs float, at each reduced dimension.
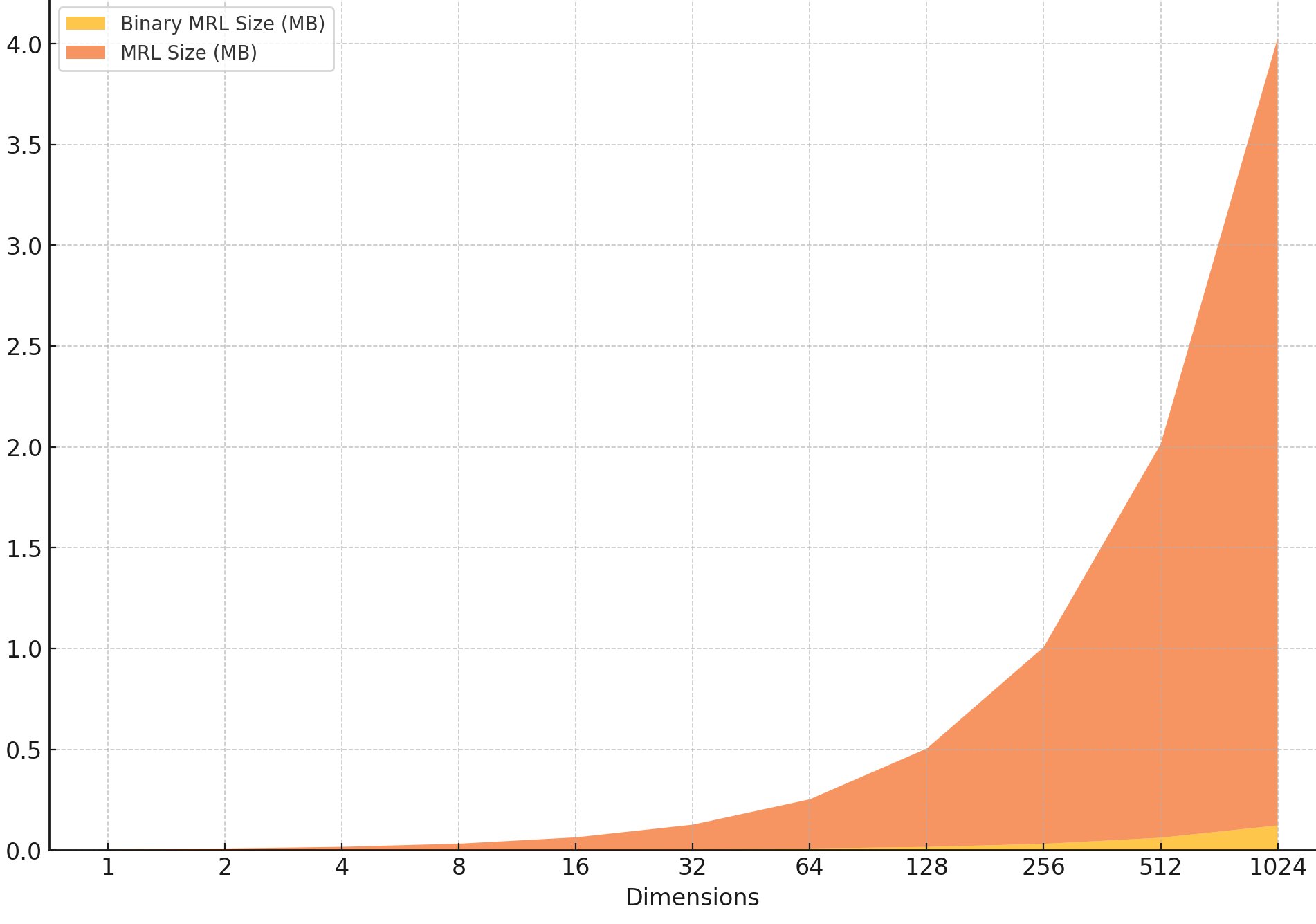
After 256 dimensions I hit true diminishing returns. Arguable we may lose finesse of semantic context through dimensionality reduction, but isn’t that what PCA is all about anyway? I’ve made a switch. Going forward lean a mean!
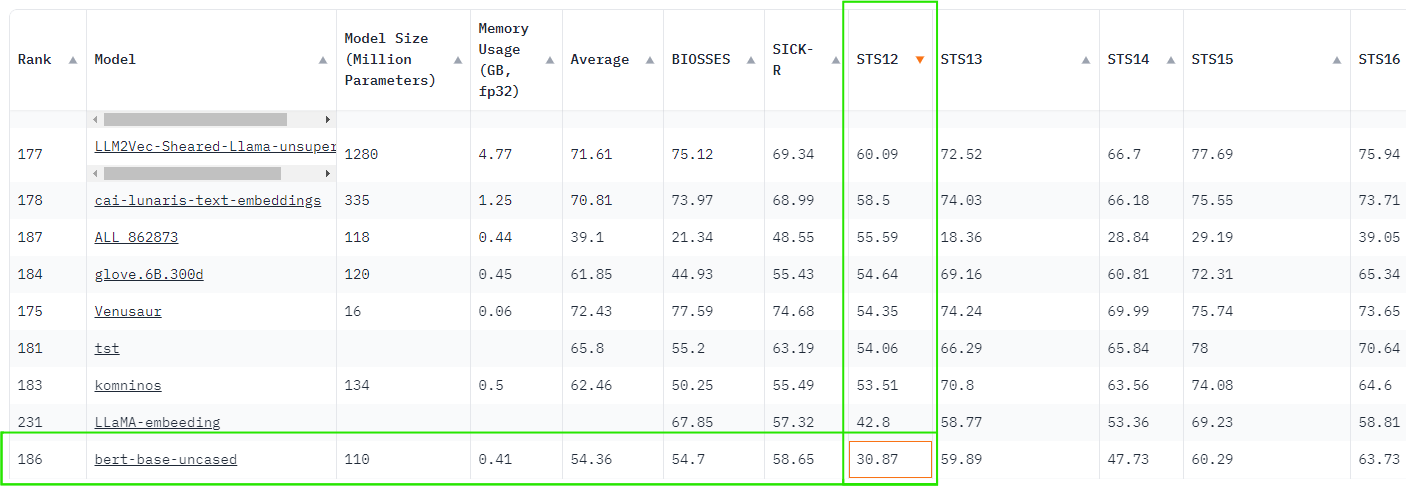
The OG BERT is at 30.87 on MTEB leaderboard which puts it on par with a binary 8-dimensional embedding of a modern embedding model. Ridiculous!
Here I apply my research to make a simple search engine using binary embeddings with dimensionality reduction to 256 using matryoshka representation learning method.
 Dan Petrovic ·
Sep 05, 21:09
Dan Petrovic ·
Sep 05, 21:09
Sign in with Google to comment.