Explore how to use Otsu's algorithm to solve the problem of inconsistent confidence thresholds in search-query intent classifiers using dynamic, per-label tuning.
When you're running search-intent classifiers in production, setting a single confidence threshold is a recipe for a headache. Some labels are common and score generously, while others are rare and score conservatively. If you set one global cutoff, you either flood your system with irrelevant results or starve your rare categories. Manually tuning thresholds for dozens of labels is a never-ending game of whack-a-mole.
A clever solution actually comes from image processing: Otsu’s algorithm. Originally built to separate the foreground of an image from its background, it can do the exact same thing for search data. Think of your label scores as a mountain range. On one side, you have likely negatives. On the other side, you have likely positives. Otsu's algorithm slides across this landscape and finds the deepest valley between them. This valley becomes the perfect, custom threshold for each individual label, adapting automatically without any hand-tuning.
To make this production-ready, you just need a couple of guardrails. Set a global minimum floor to block noise, and add a fallback rule that assigns the single highest-scoring label if a query gets left with nothing. This approach eliminates unlabeled rows, keeps noise in check, and scales effortlessly to any taxonomy. It solves dynamic thresholding once and for all, with no manual babysitting required.
Arbitrary label search-query intent classifiers spit out a confidence score per label.

On clean demos you set one global cut-off say 0.50 and move on.
In production:
Manual tuning per label quickly turns into a never-ending whack-a-mole, especially when the taxonomy is customized client-by-client (e.g., SaaS today, Gaming tomorrow).
Here’s an example:
Query: “used caravan shower cubicles for sale near me”
data = [
(“LOCAL”, 0.9697265625),
(“PRODUCT”, 0.83837890625),
(“CATEGORY”, 0.39892578125),
(“TRANSACTIONAL”, 0.09222412109375),
(“INFORMATIONAL”, 0.000947475433349609),
(“PROMO”, 0.00080108642578125),
(“BRANDED”, 0.00034332275390625),
(“SUPPORT”, 0.000284671783447266),
(“NAVIGATIONAL”, 0.000205039978027344),
]
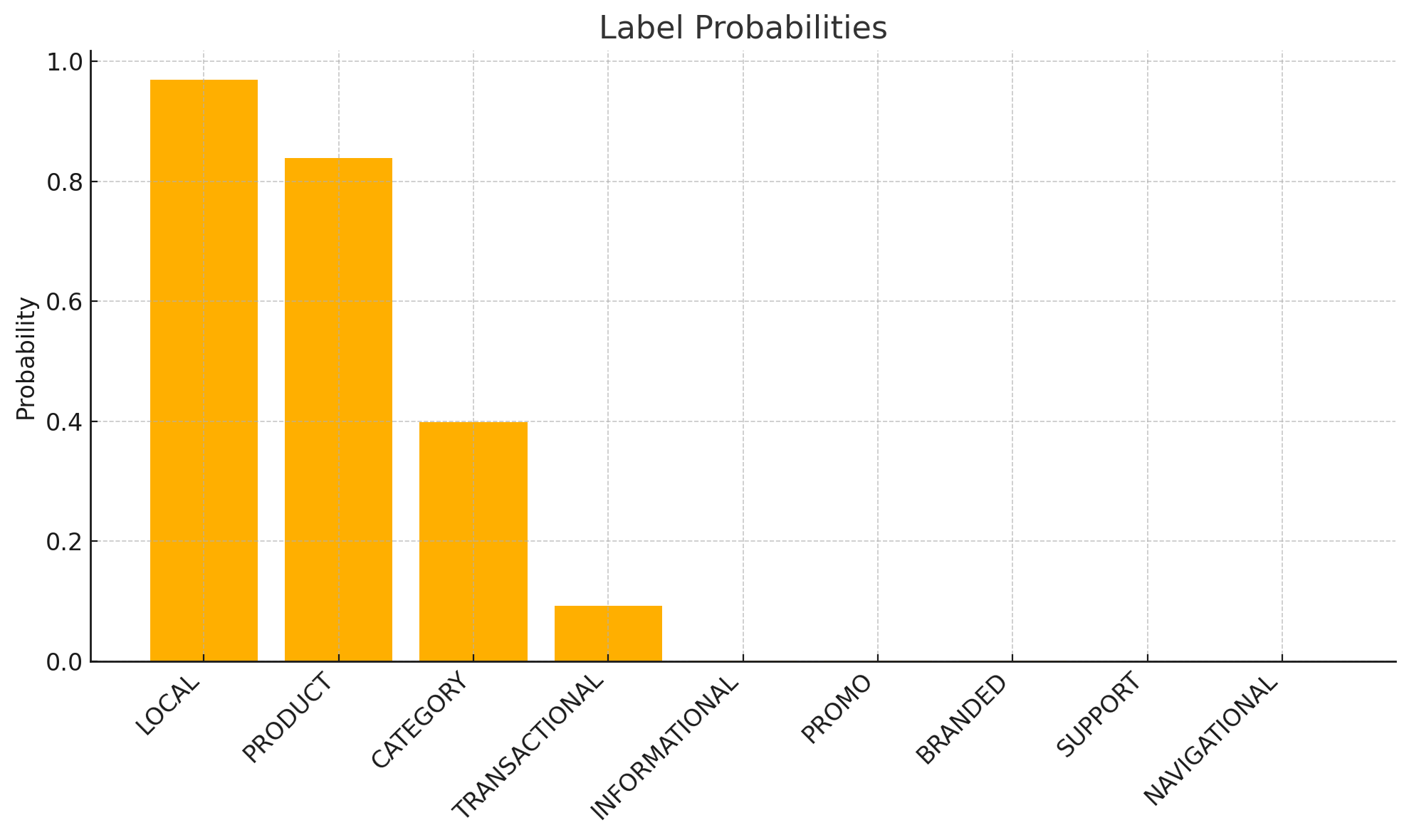
Well that’s easy you might say. It’s quite obvious we can set threshold to 0.4 and that sets LOCAL, PRODUCT and CATEGORY. We miss TRANSACTIONAL but otherwise keep the floodgates of irrelevant stuff out for other labels at that threshold value.
Right? Cool now let’s do another query.
Query: “square tents”
data = [
(“PRODUCT”, 0.84423828125),
(“CATEGORY”, 0.31689453125),
(“SUPPORT”, 0.00284576416015625),
(“TRANSACTIONAL”, 0.000590801239013672),
(“PROMO”, 0.000458240509033203),
(“BRANDED”, 0.00039362907409668),
(“INFORMATIONAL”, 0.000348806381225586),
(“LOCAL”, 0.000211477279663086),
(“NAVIGATIONAL”, 0.000198721885681152),
]
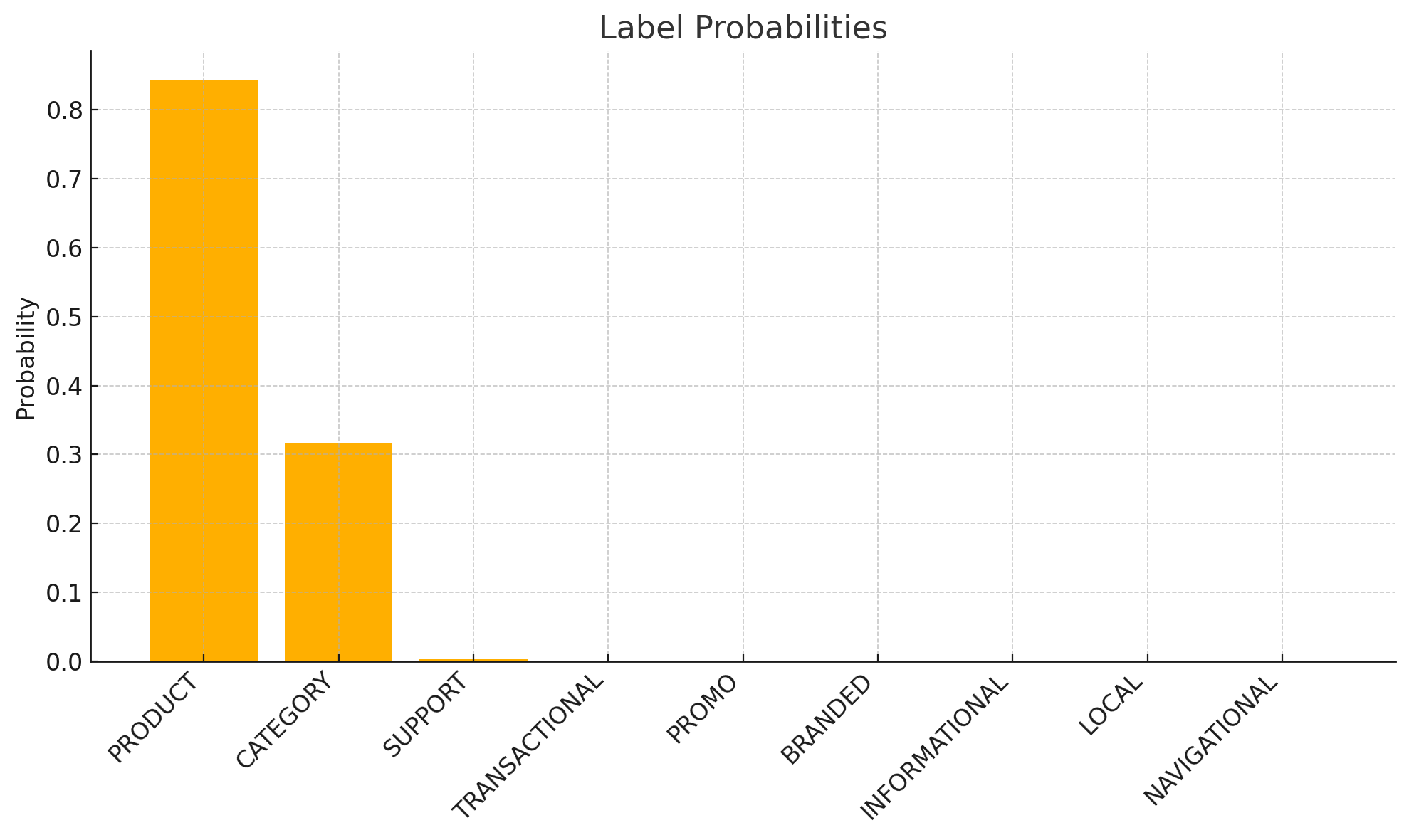
We’ll just use the same threshold. Right? Wrong! You now have to lower it to 0.3 to include the CATEGORY label. This is because all labels have different and inconsistent confidence thresholds.
Now imagine fiddling around like this with 100,000 queries?
No thanks.
Otsu’s algorithm (1979) was built for image segmentation: find the gray-level that best separates foreground and background by maximizing between-class variance.
Translate to NLP:

Picture your label-scores as a mountain range drawn by a histogram:
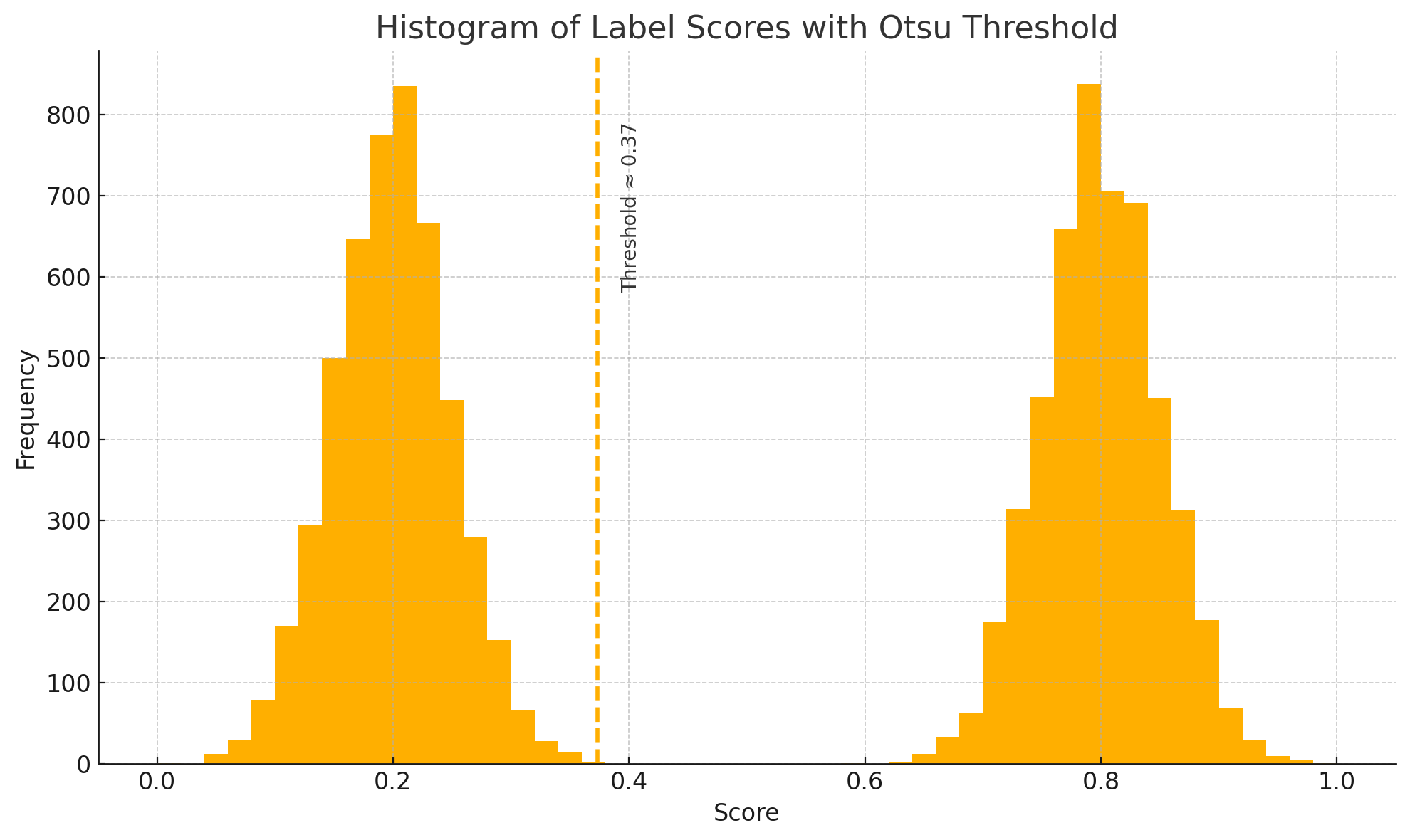 Histogram illustrates two peaks (likely negatives on the left, positives on the right) with the dashed vertical line marking the Otsu-derived threshold at the lowest point between them.
Histogram illustrates two peaks (likely negatives on the left, positives on the right) with the dashed vertical line marking the Otsu-derived threshold at the lowest point between them.
Otsu simply slides a vertical ruler across that landscape, computes how well the left side and right side each cluster, and stops at the deepest point of the valley, the most natural dividing line. That valley score becomes the dynamic threshold for that label.
scores are that label’s confidences across the full corpus.
Recalculate thresholds every time you re-score so they drift with model upgrades or seasonal traffic changes.
Noise stayed manageable while eliminating unlabeled rows.
Dynamic thresholding solved without manual babysitting.
 Dan Petrovic ·
Jul 09, 23:11
Dan Petrovic ·
Jul 09, 23:11
Sign in with Google to comment.