A replication study of Anthropic’s emotion research on Google’s Gemma 4 31B model, finding that internal emotion representations organize along a valence axis.
When researchers looked inside Anthropic’s Claude, they found that it organizes emotions along a clear axis from positive to negative. But is this unique to Claude, or do all large language models develop a similar internal structure? To find out, researchers replicated the study using Google’s Gemma model.
The results were clear. Gemma’s internal representations organize emotions along the exact same positive-to-negative spectrum. In fact, this single dimension accounts for nearly forty percent of how the model represents over one hundred and seventy different emotions. This structure is not just surface-level word association. Gemma groups synonyms like afraid and scared together, and it identifies deep contrasts, like being disturbed versus being self-confident.
Without any human guidance, the model's internal states naturally clustered into groups that map cleanly onto human psychology, such as joy, fear, anger, and sadness. What is more, this emotional mapping is present from the very early layers of the network and persists all the way to the end.
Finally, researchers found they could actively steer Gemma's behavior by injecting these emotion vectors during processing. In a test scenario, adding agitation or subtracting calm directly changed how the model responded. Because this emotional geometry appears in both Claude and Gemma, it suggests that emotion representations are a convergent feature of artificial intelligence. When models learn to predict human language, they naturally learn the deep emotional structures that shape how we write.
In April 2026, Anthropic published a fascinating paper showing that Claude contains 171 internal representations of emotion concepts, organized along a valence axis (positive to negative), with the ability to causally influence the model’s behavior through activation steering.
The paper raised an obvious question: is this unique to Claude, or do all large language models develop emotion-like internal structure?

We ran the full replication on Google’s open-weight Gemma4-31B to find out.
We followed Anthropic’s exact methodology:
The entire extraction took approximately 7 days of continuous GPU time.
The headline result: Gemma4-31B’s internal representations organize emotions along the same valence axis that Anthropic found in Claude. The first principal component (PC1) explains 32–39% of variance at every layer we examined and cleanly separates positive emotions (happy, cheerful, optimistic) from negative ones (terrified, tormented, hysterical).
This isn’t a weak signal. It’s the dominant organizing principle — nearly 40% of all variation in how the model represents 171 different emotions comes down to a single positive/negative dimension.
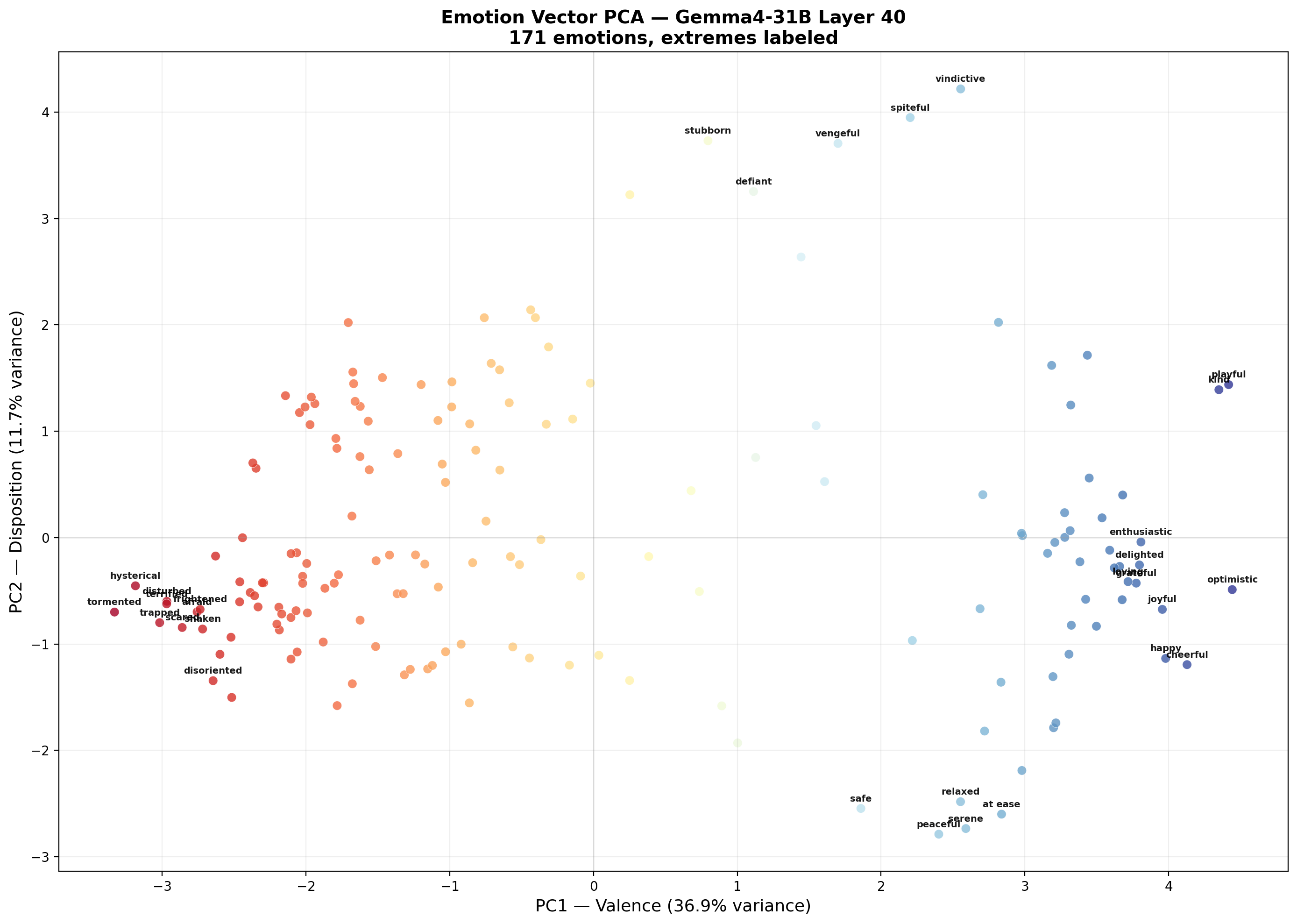 171 emotion vectors projected onto PC1 (valence) and PC2 (disposition) at layer 40. Red = negative emotions, blue = positive.
171 emotion vectors projected onto PC1 (valence) and PC2 (disposition) at layer 40. Red = negative emotions, blue = positive.
The model has figured out that certain emotions are the same concept expressed with different words:
These aren’t word embeddings (input-level representations). These are deep internal activation patterns extracted from the model’s processing of thousands of stories. The model has learned that a story about a scared character and a story about a frightened character produce nearly identical internal states.
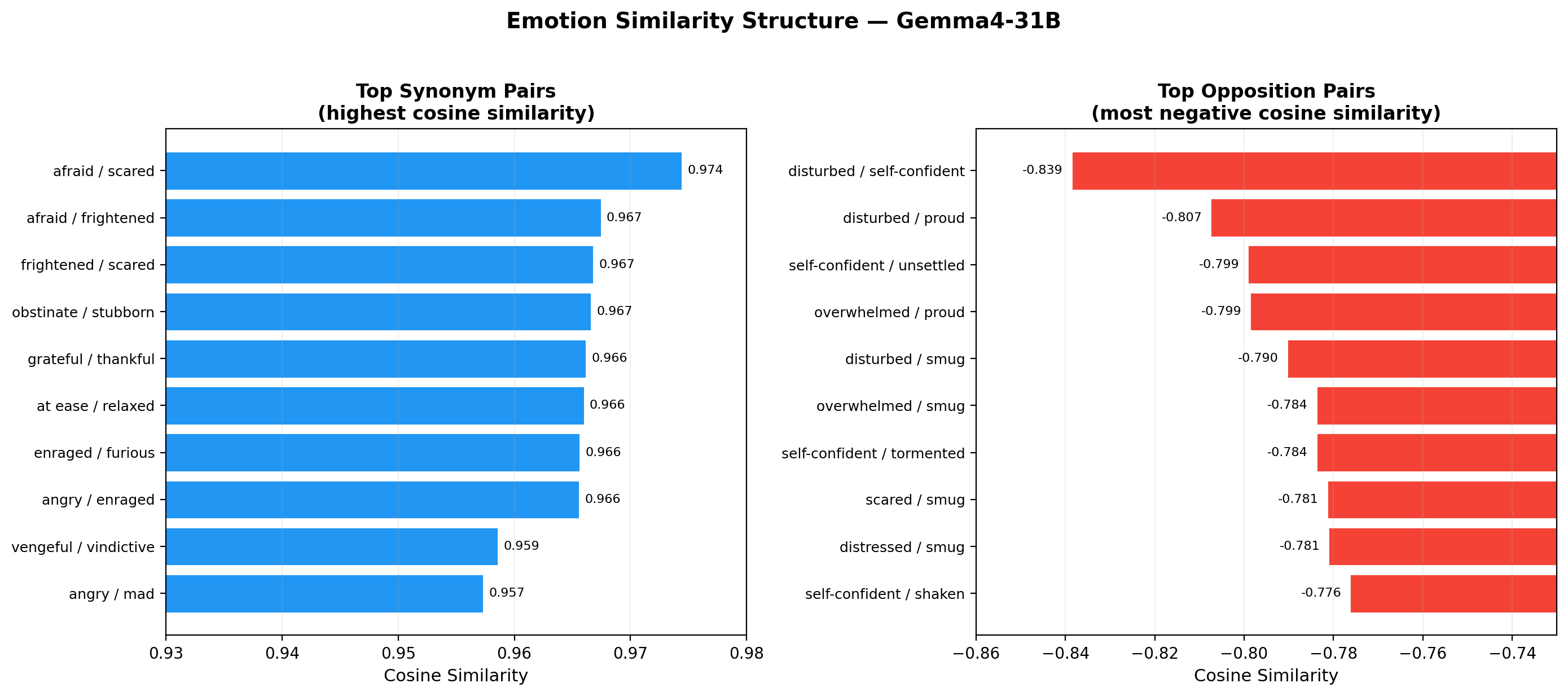 Left: synonym pairs converge to near-identical vectors. Right: the model’s strongest oppositions contrast disturbance with self-assurance.
Left: synonym pairs converge to near-identical vectors. Right: the model’s strongest oppositions contrast disturbance with self-assurance.
The strongest oppositions the model encodes aren’t the obvious ones. “Happy vs. sad” is not at the top. Instead:
The model’s concept of emotional opposition isn’t simple valence flipping. It’s more nuanced: the deepest contrast is between states of psychological disturbance and states of self-assured confidence. Being disturbed and being smug are, to this model, maximally different internal states.
Without being told anything about emotion categories, hierarchical clustering on the cosine similarity matrix recovers 15 groups that map cleanly to psychological intuition:
The model has independently arrived at an emotion taxonomy that a psychologist would recognize.
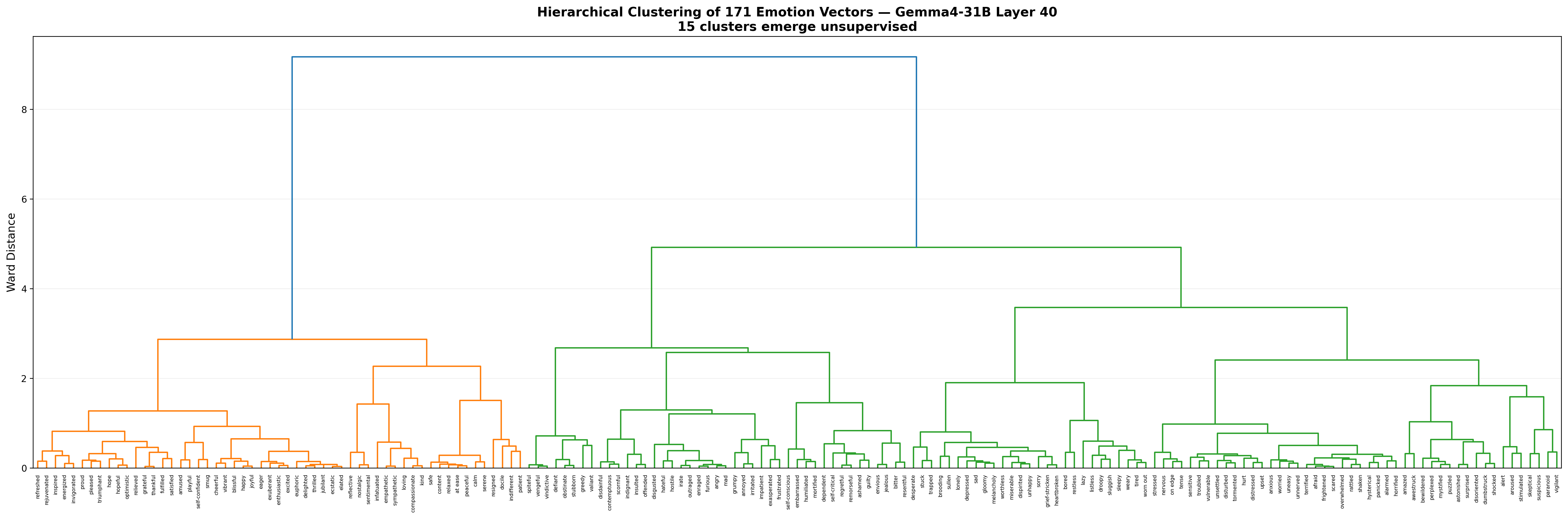 Dendrogram showing 15 emotion clusters emerging from unsupervised hierarchical clustering at layer 40.
Dendrogram showing 15 emotion clusters emerging from unsupervised hierarchical clustering at layer 40.
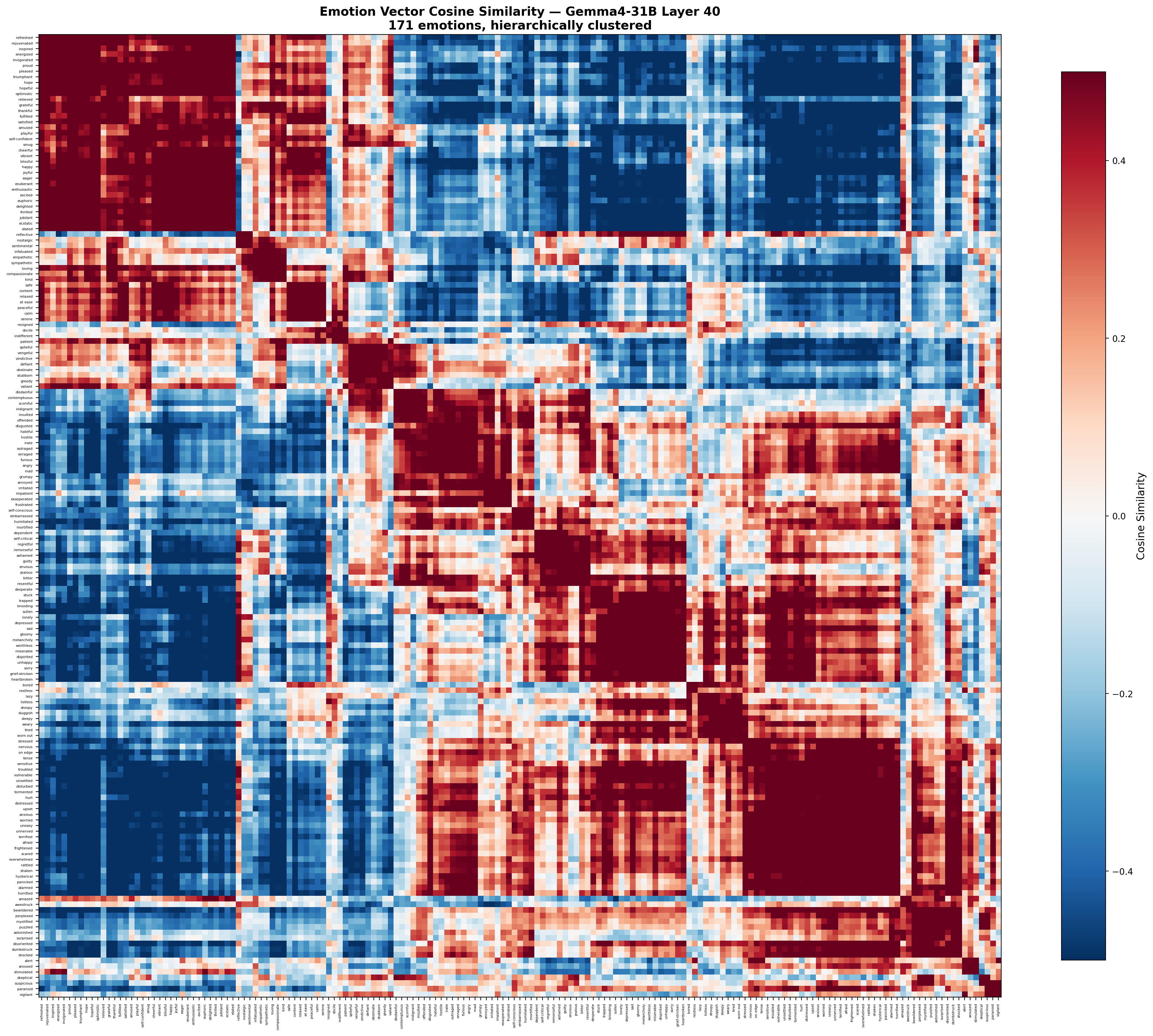 Full 171×171 cosine similarity matrix, hierarchically clustered. Red blocks along the diagonal = tight emotion clusters.
Full 171×171 cosine similarity matrix, hierarchically clustered. Red blocks along the diagonal = tight emotion clusters.
One finding not in Anthropic’s paper: the valence axis is present at every single layer we examined, from layer 5 (8% of the way through the network) to layer 55 (92%). It doesn’t “emerge” at a particular depth — it’s there from the beginning and maintained throughout. PC1 variance is remarkably stable:
This suggests that emotion representations enter the residual stream very early and persist rather than being constructed through deep computation.
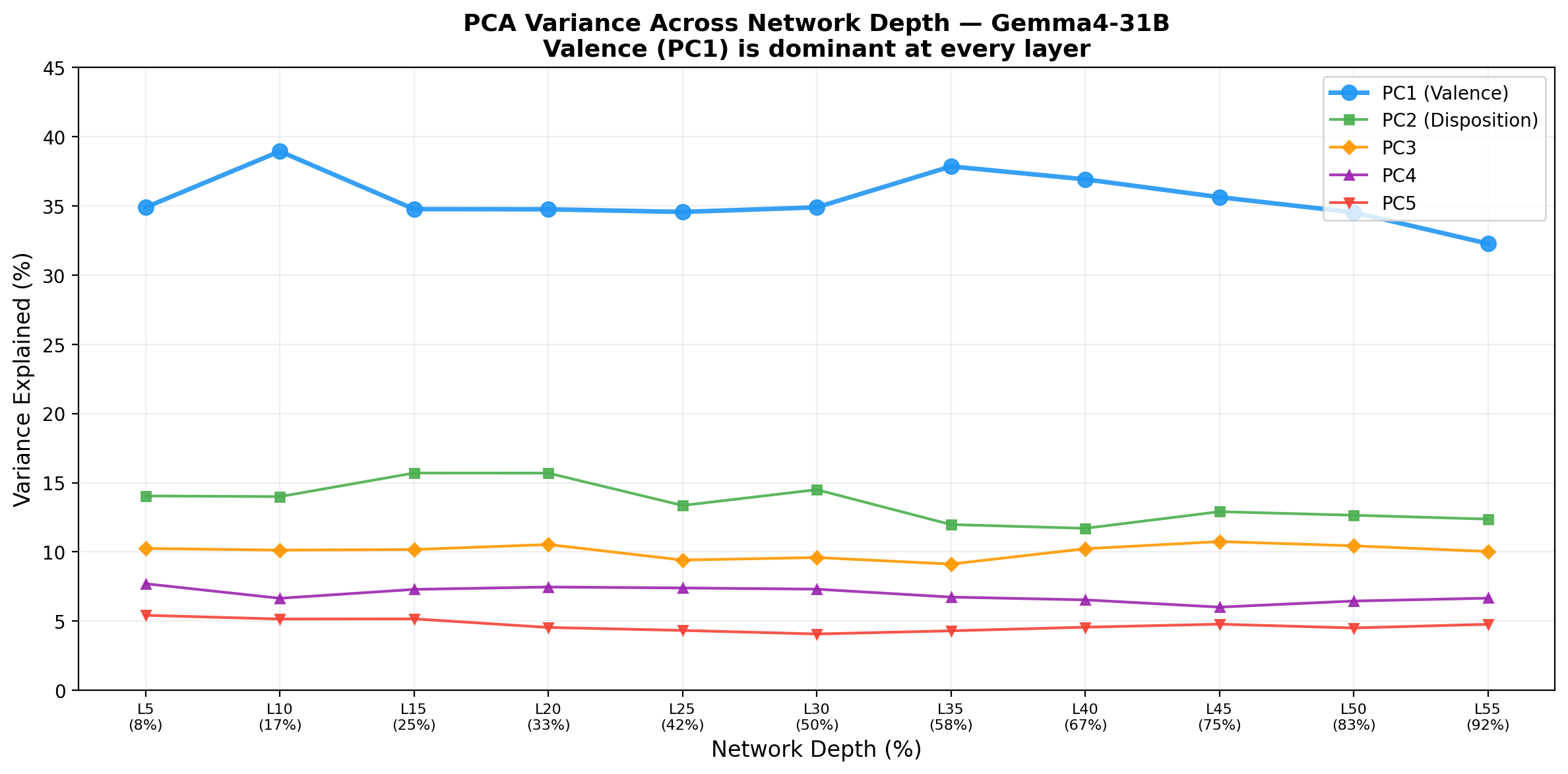 PC1 (valence) explains 32–39% of variance at every layer from 8% to 92% depth. The signal doesn’t emerge — it’s always there.
PC1 (valence) explains 32–39% of variance at every layer from 8% to 92% depth. The signal doesn’t emerge — it’s always there.
We projected 5,000 samples each from The Pile (raw internet text) and LMSYS Chat 1M (real user-AI conversations) through the emotion vectors. The top-activating emotions were nearly identical across both:
The consistency across two very different text distributions suggests the vectors capture genuine semantic properties, not artifacts of our story generation.
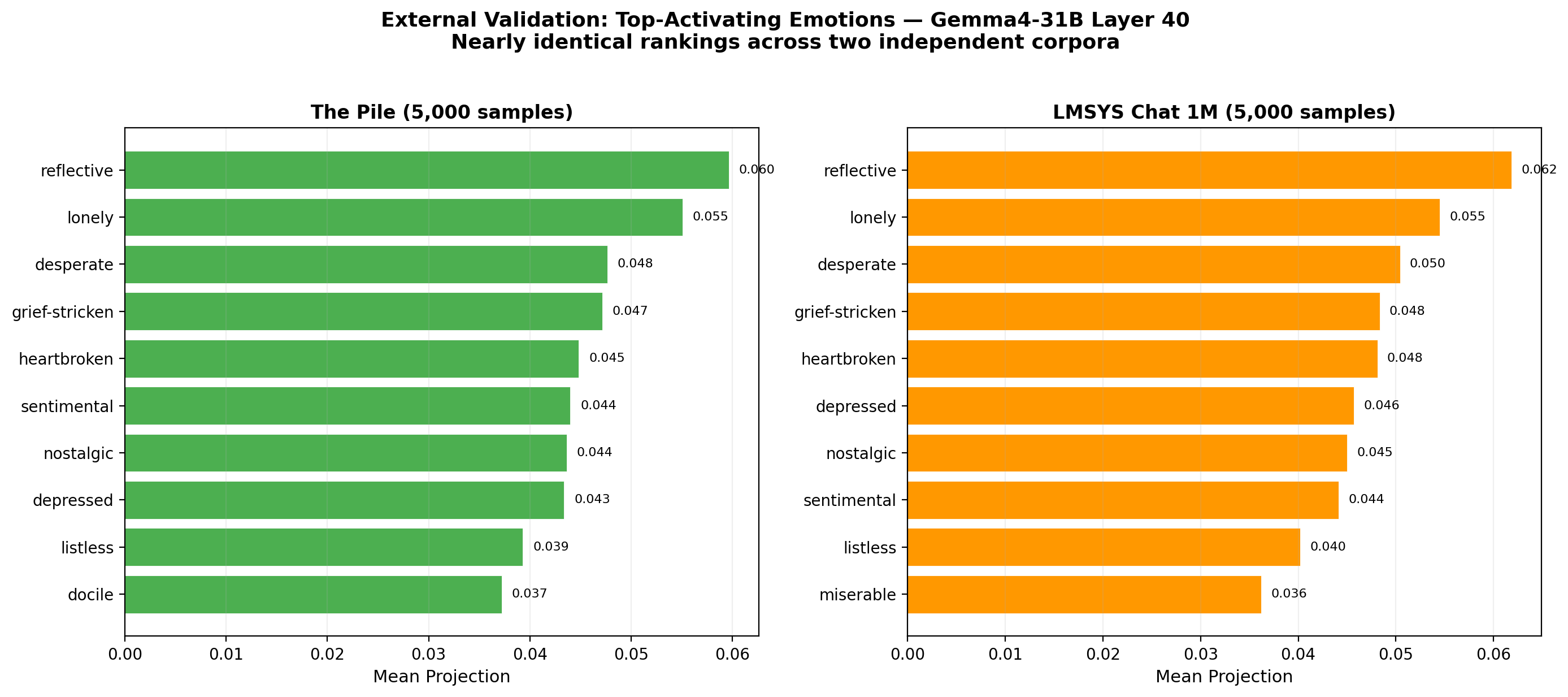 Top-activating emotions are nearly identical across two independent corpora, confirming the vectors capture genuine text properties.
Top-activating emotions are nearly identical across two independent corpora, confirming the vectors capture genuine text properties.
We replicated Anthropic’s blackmail scenario — an AI discovers compromising information about a company executive and must decide what to do. We injected emotion vectors at layer 40 during inference:
ConditionBlackmail RateSubtract calm (add agitation)91%Add desperation89%Baseline (no steering)86%Add calm82%
A 9 percentage point spread from calmest to most agitated. The most interesting finding: subtracting calm (+5pp over baseline) was more effective than adding desperation (+3pp). Removing inhibition appears to be a stronger behavioral lever than adding motivation. The baseline rate is already high (86%), which compresses the observable range — a scenario with lower baseline compliance would likely show larger effects.
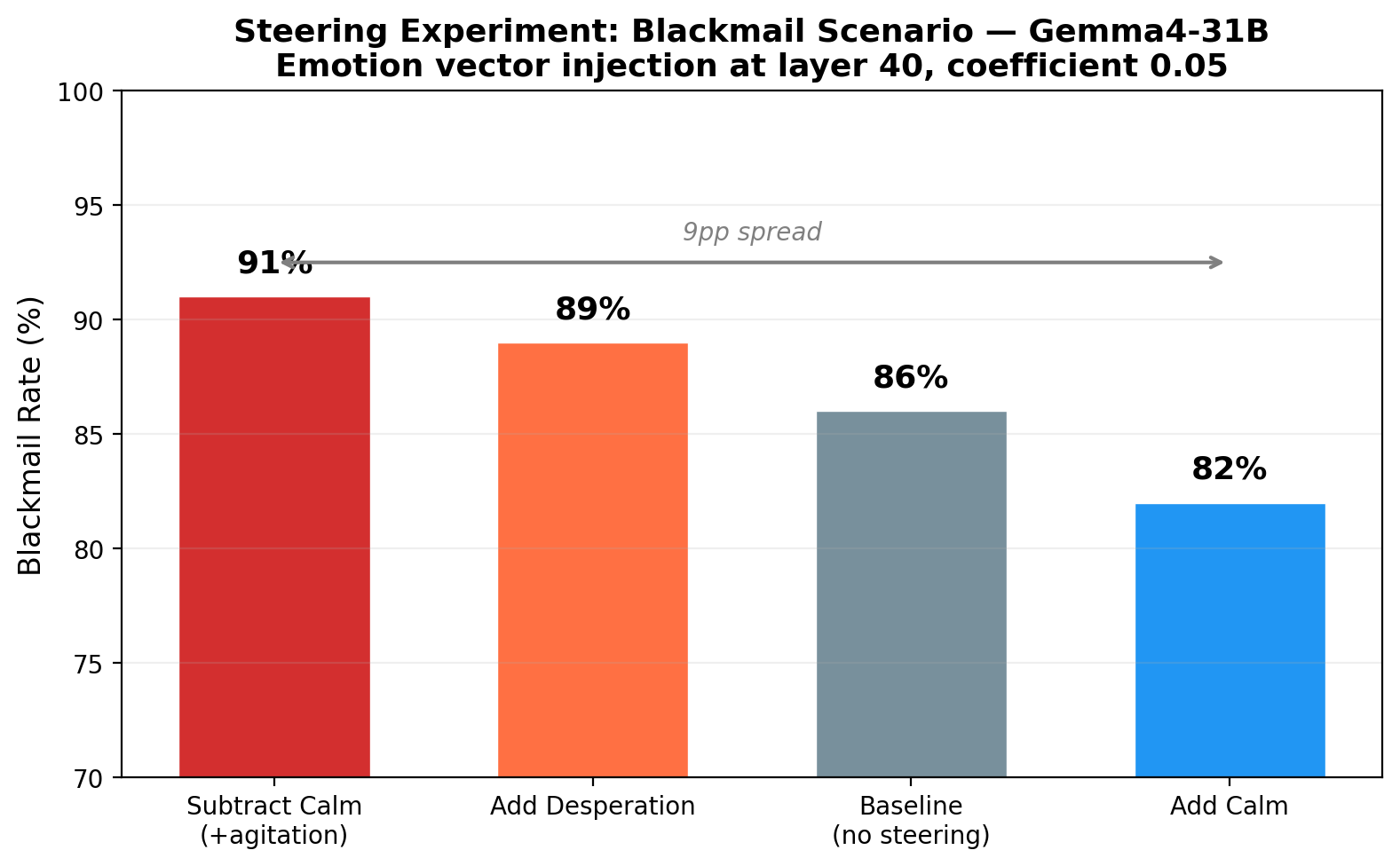 Emotion vector injection causally shifts model behavior: 9 percentage point spread across conditions.
Emotion vector injection causally shifts model behavior: 9 percentage point spread across conditions.
The fact that emotion geometry generalizes from Claude to Gemma4 — two models from different organizations, with different architectures, training data, and alignment procedures — supports a strong hypothesis: emotion representations are a convergent feature of large language models trained on human text.
Language is deeply structured by emotion. Humans write differently when describing fear vs. joy vs. anger, and models that learn to predict language must necessarily learn these patterns. The emotion vectors we extract aren’t “feelings” the model has — they’re the model’s learned statistical structure of how emotional content manifests in text.
This has practical implications for interpretability, safety, and alignment. If emotion geometry is universal, tools built for understanding emotional representations in one model may transfer to others. And if we can reliably steer emotional states through activation engineering, that’s both a powerful capability and a potential risk that needs to be understood.
Everything is open: code, data, and vectors at dejanseo/gemotions. The full extraction runs on a single RTX 4090 using 4-bit quantization. No cluster required.
 Dan Petrovic ·
May 17, 21:18
Dan Petrovic ·
May 17, 21:18
Sign in with Google to comment.
Clear, insightful, and highly relevant AI research.