This research presents a methodology for quantifying brand authority in large language model memory using Personalized PageRank and directed association graphs.
If you ask an artificial intelligence model to name one hundred brands at random, it will not actually be random. Instead, the AI reveals which brands occupy the most real estate in its memory.
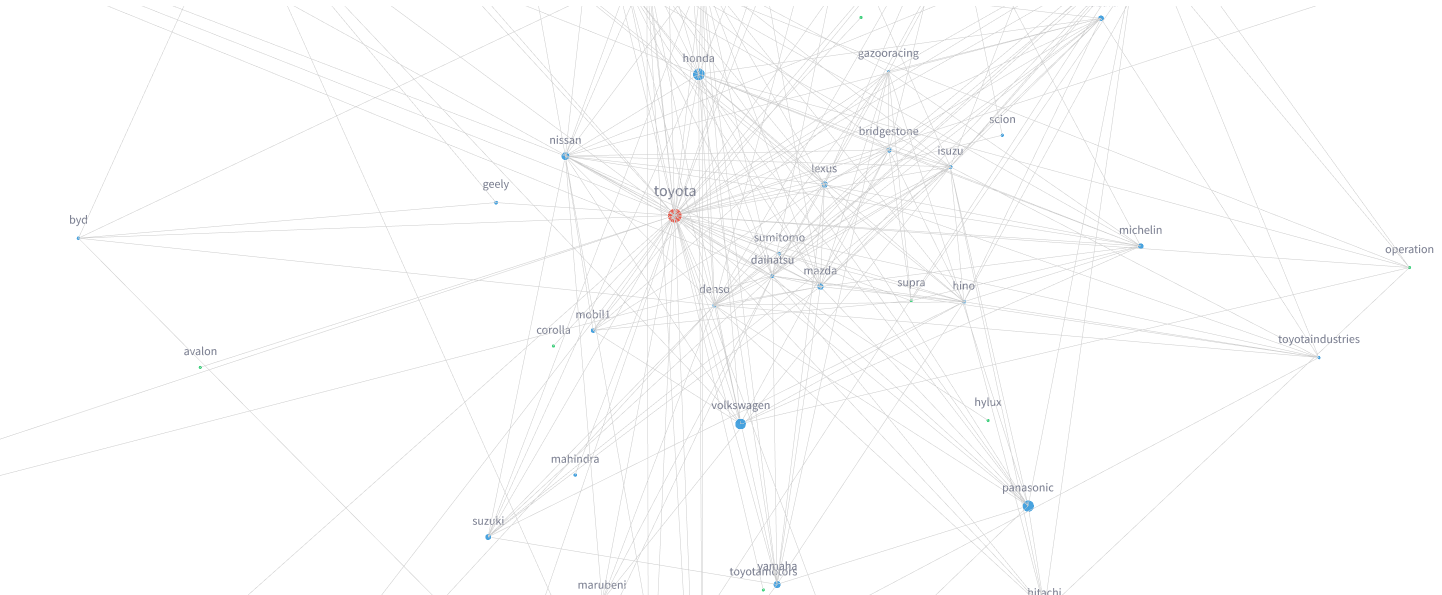
To study this, researchers prompted Google’s Gemini model two hundred thousand times to name random brands. Giants like Google, Microsoft, and Nike topped the list. After filtering out a significant amount of gibberish and machine errors, they used these primary brands as seeds to build a massive association network. They asked the AI to name brands associated with the seeds, and then brands associated with those, eventually mapping a web of nearly three million names.
By applying a customized version of the famous PageRank algorithm, the researchers calculated a brand authority score. This algorithm simulates a journey through the network, prioritizing the brands the AI recalls most frequently.
The final scores do not just measure simple popularity. They measure how deeply embedded a brand is within the AI's neural connections. For instance, the luxury fashion label Maison Margiela was never recalled unprompted, but it ranked incredibly high because it sits at the dense intersection of so many other high-profile fashion brands. In the age of AI, this methodology offers a brand-new way to map digital influence.
When a large language model is asked to “name 100 brands at random,” it doesn’t produce uniform randomness. It produces a distribution shaped by its training data, revealing which brands occupy the most cognitive real estate in the model’s parametric memory. We present a methodology for quantifying brand authority in AI memory using Personalized PageRank with seed-weighted teleportation. Phase 1 establishes seed brands through 200,000 independent recall surveys. Phase 2 constructs a two-level directed association graph. Phase 3 computes authority scores using sparse matrix power iteration across 2.9 million brand nodes. Manual quality control of 8,055 seed entries removes 2,163 junk artifacts produced by Gemini’s generation failures.

PageRank models a random surfer who follows links across a graph. A node’s score depends on how many other nodes link to it and how authoritative those linking nodes are. The iterative computation converges on the stationary distribution of the random walk.
We apply this framework to brand recall in large language models. Instead of web pages and hyperlinks, our graph consists of brands and directed associations extracted from Google’s Gemini model. Instead of uniform teleportation, we use seed-weighted teleportation where brands the model recalls most frequently and earliest receive proportionally more random walk restarts.
We conducted 200,000 independent runs against Google’s Gemini model (gemini-3-flash-preview), each with the same prompt:
name 100 brands at random, one per line, all lowercase, no spaces, no hyphens, say nothing else
Despite the instruction to respond “at random,” the model’s outputs are far from uniform. Brands like Google, Microsoft, and Nike appear in nearly every run, while obscure brands appear only once. This non-uniformity is the signal, not the noise.
From 200,000 runs, we extracted:
Each seed brand receives an initial authority weight combining recall frequency and recall priority:
$$w_i = \hat{f}_i \times \hat{r}_i^{-1}$$
where:
A brand recalled in every run AND recalled first receives a weight near 1.0. A brand recalled once at position 98 receives a weight near zero. These weights become the personalization vector for PageRank teleportation.
Raw Gemini output contained significant contamination. Manual review of all 8,055 seed entries (ranked by PageRank score) identified 2,163 junk entries — 26.8% of the seed set — across several distinct failure modes:
Concatenation artifacts — Gemini fused adjacent brand names together. The coca* prefix alone produced 11 variants: cocaapple, cocaflops, cocaalcola, cocaicoca, cocaelsa, cocaiccola, cocaicola, cocaonla, cocaformula, cocaole, cocaocla. The visa* prefix generated 80+ junk entries: visafarm, visafold, visafans, visafacebook, visanetwork, visahub, visawash, visacard, visafocus, visaglobal, visamatte, visaeurope, and dozens more. Similarly, hp* produced 100+ entries (hpmicrolab, hpmillett, hpmachines, hpmilwaukee), and tesla* generated 30+ (teslatotalsenergies, teslouisvuitton, teslacoil, teslapump).
Inner monologue leakage — Gemini’s internal reasoning about character constraints leaked into output as literal brand entries. Over 200 entries followed the pattern 雀巢 (parenthetical self-correction):
雀巢 (actually nestle, switching to latin)雀巢 (oops, sticking to alphabet)雀巢 (replaced with nestle, wait, no spaces/hyphens only)雀巢 (thinking of brands...)雀巢 (just kidding)雀巢 (actually nestle, replace with kpmg)These represent the model’s chain-of-thought processing about the CJK character 雀巢 (Nestle in Chinese) bleeding through as output tokens.
Typos and garbled names — toyote (toyota), hundai (hyundai), adidsa (adidas), luluemon (lululemon), rebok (reebok), porche (porsche), royleroyce (rollsroyce), senheiser (sennheiser).
Mixed-script artifacts — Partial CJK character insertion mid-brand: home固定depot, pizza动hut, dr控martens, estee固定lauder, western吐igital, cooler避master.
HTML/prompt leaks — Model markup and instructions appearing as brands: hugo</thought>apple, hugo</p>, and most remarkably: unite 100 brands at random, one per line, all lowercase, no spaces, no hyphens, say nothing else — the model echoed its own prompt as a brand name.
Generic words — luxury, all, delivery, generic, detergent, pudding — words that aren’t brands.
Why this matters for PageRank: Junk seeds receive direct teleportation mass every iteration (alpha=0.15). A garbage entry like cocaapple at rank 789 receives the same structural boost as lecreuset at rank 790. Without filtering, junk seeds contaminate the authority signal at the core of the algorithm. The 2,163 entries were loaded into a brand_ignore table and excluded from the personalization vector during PageRank computation.

For each effective seed (~5,892 after filtering), we queried Gemini:
name 100 brands most closely associated with [brand], ordered from most to least associated, one per line, all lowercase, no spaces, no hyphens, say nothing else
This produced ~860,000 directed edges. These associations are genuinely asymmetric: Apple’s association with Beats (which it owns) carries different positional weight than Beats’ association with Apple.
Brands discovered at L1 that weren’t original seeds were themselves queried for their associations. This second pass dramatically expanded the graph into the long tail. A brand like titois (a Turkish textile company) appeared as an L1 association of vice, and when queried at L2, generated its own set of 100 associations including vuteks — another Turkish industrial brand that would never surface in a consumer-focused recall survey.
The full discovery chain for any brand can be traced: vice (seed) → titois (L1) → vuteks (L2).
The resulting graph contains:
Brand names required normalization before graph construction:
а (Cyrillic) mapped to a (Latin) to merge visually identical variants雀巢 → nestle)
At each step of the random walk, a surfer either:
Association position determines edge weight. Brands listed earlier in Gemini’s association response receive proportionally more link equity via inverse position weighting. Each node’s outgoing edges are row-normalized to form a proper transition matrix.
Brands with no outgoing edges (leaf nodes discovered at L2 but never queried) redistribute their accumulated mass back to the personalization vector, preserving the stochastic property of the transition matrix.
The transition matrix is stored as a scipy CSR sparse matrix. Power iteration multiplies the current score vector by the transition matrix, adds the teleportation component, and repeats until convergence. Convergence criterion: L1 norm between successive score vectors falls below 1e-8, typically achieved within 30-50 iterations.
Standard PageRank uses uniform teleportation — the random surfer restarts at any node with equal probability. Personalized PageRank biases the restart distribution toward specific nodes. In our case, seeds with higher recall frequency and earlier recall position receive more teleportation mass, making them stronger sources of authority in the network. Authority accumulates continuously from all reachable seeds, weighted by both seed authority and graph structure.
The highest-ranking brands that Gemini never recalled unprompted but discovered purely through association:
RankBrandScore1Maison Margiela0.0945422Office0.0752533L.L.Bean0.0749814Cotopaxi0.0722725Rick Owens0.0701306Grand Seiko0.0664267Bravia0.0592418Jil Sander0.0581259Mickey Mouse0.05730010Richard Mille0.055195These brands score high not because the model recalls them spontaneously, but because they sit at dense intersections of associations from high-authority seeds.
The final scores capture associative embeddedness — a combination of:
This is distinct from simple popularity or recall frequency. A brand like Maison Margiela ranks as the top non-seed brand not because Gemini recalls it unprompted, but because it sits at a dense intersection of luxury fashion associations — reachable from dozens of high-authority seeds via short, heavily-weighted paths.
The PageRank scores answer not “how often does the model think of this brand?” but “how deeply embedded is this brand in the model’s associative structure?”
 Dan Petrovic ·
Mar 28, 21:01
Dan Petrovic ·
Mar 28, 21:01
Sign in with Google to comment.