DEJAN-LM is an AI content detection model trained on 20 million sentences, using a combined deep learning and heuristic approach to identify advanced AI text.
AI models are getting so advanced that standard detection tools can no longer keep up. Text from the latest systems easily fools them. To tackle this, we brought AI detection in-house.
We started with our own base model, DEJAN-LM, which is an expert in web articles. We pre-trained it on ten million sentences from top-quality websites, and then fine-tuned it on a twenty-million sentence dataset split evenly between human and AI-generated content.
But even with this advanced setup, the newest OpenAI models managed to fly under the radar. Our deep-learning model struggled to detect content from the elusive GPT-o-four-mini.
To solve this, we went old school. We analyzed our twenty-million sentence dataset to identify and weigh the top one thousand words for both human and AI writing. By combining this simple vocabulary heuristic with our deep-learning model, we saw a massive breakthrough.
The detection confidence for that elusive new GPT model jumped from just around twenty-one percent to over sixty-eight percent. By merging modern deep learning with classic heuristics, we can confidently flag AI-generated content once again.
As models advance, AI content detection tools are struggling to keep up. Text generated by the latest Gemini, GPT and Claude models is fooling even the best of them.
We’ve decided to bring AI content detection back in-house in order to keep up. Each time a new model comes out the classifier needs a fine-tune on that model’s output.
Our base model, DEJAN-LM was pre-trained on a 10,000,000 sentence dataset using masked language modelling (MLM) on top quality content from websites with excellent editorial practices. DEJAN-LM is a web article expert.
The model was fine-tuned for AI content detection on a 20,000,000 sentence dataset, 50% original human content, 50% AI paraphrase or derivative content.
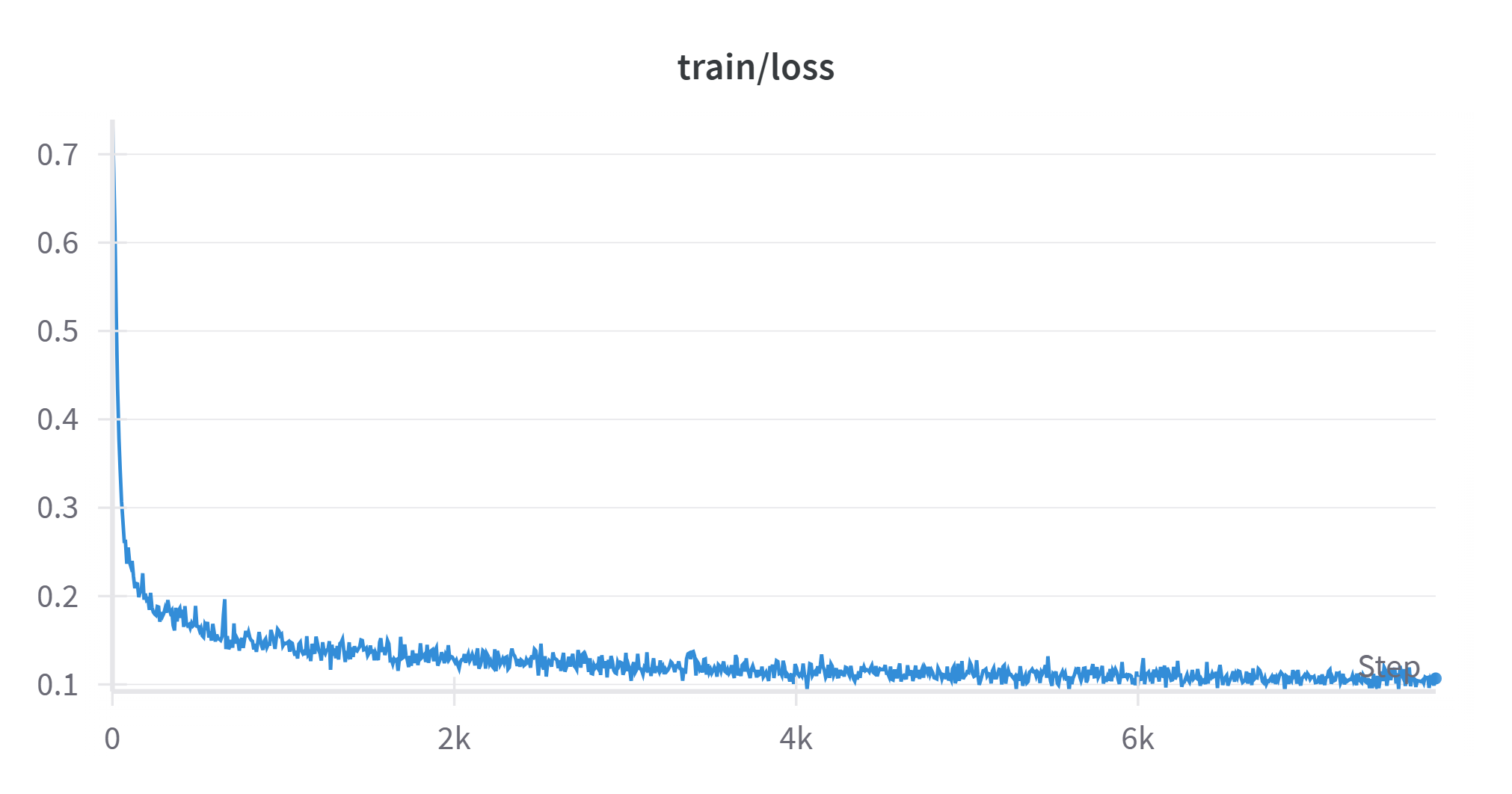






It’s clear that OpenAI’s latest model flies under the radar and avoids deep-learning based detection so we went old school. The 20,000,000 sentence dataset was processed to define top 1000 words for each class sorted by dataset count. We then normalise their values allowing for non-discriminating words to self-eliminate.
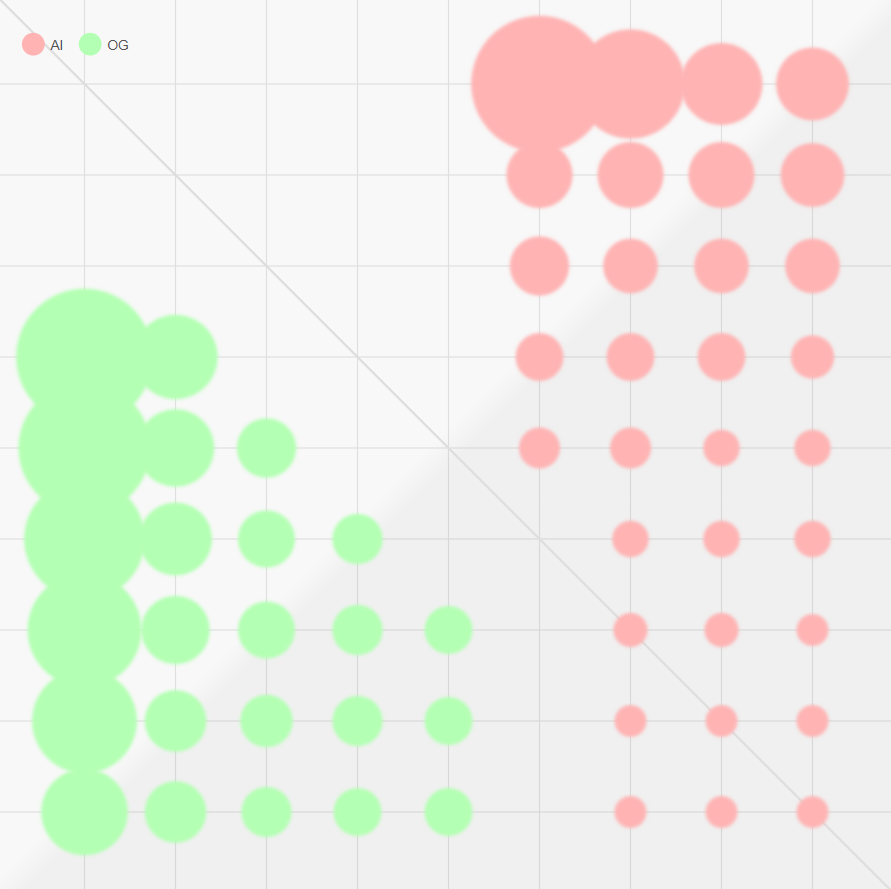
The two lists of top words and their weights were used in a simple ranking algorithm to help our deep learning model where it struggles.

As a result the classification confidence for the elusive GPT-o4-mini went from mere 20.7% all the way to 68.1% which puts it in the “Yes, it’s AI generated!” category.
 Dan Petrovic ·
Apr 17, 22:52
Dan Petrovic ·
Apr 17, 22:52
Sign in with Google to comment.